Reference
- About This Guide
- I Advanced Administration
- II System
- 8 32-Bit and 64-Bit Applications in a 64-Bit System Environment
- 9 Introduction to the Boot Process
- 10 The
systemdDaemon - 11
journalctl: Query thesystemdJournal - 12 The Boot Loader GRUB 2
- 13 Basic Networking
- 14 UEFI (Unified Extensible Firmware Interface)
- 15 Special System Features
- 16 Dynamic Kernel Device Management with
udev
- III Services
- IV Mobile Computers
- A An Example Network
- B GNU Licenses
13 Basic Networking Edit source
Abstract#
Linux offers the necessary networking tools and features for integration into all types of network structures. Network access using a network card can be configured with YaST. Manual configuration is also possible. In this chapter only the fundamental mechanisms and the relevant network configuration files are covered.
- 13.1 IP Addresses and Routing
- 13.2 IPv6—The Next Generation Internet
- 13.3 Name Resolution
- 13.4 Configuring a Network Connection with YaST
- 13.5 NetworkManager
- 13.6 Configuring a Network Connection Manually
- 13.7 Basic Router Setup
- 13.8 Setting Up Bonding Devices
- 13.9 Setting Up Team Devices for Network Teaming
- 13.10 Software-Defined Networking with Open vSwitch
Linux and other Unix operating systems use the TCP/IP protocol. It is not a single network protocol, but a family of network protocols that offer various services. The protocols listed in Several Protocols in the TCP/IP Protocol Family, are provided for exchanging data between two machines via TCP/IP. Networks combined by TCP/IP, comprising a worldwide network, are also called “the Internet.”
RFC stands for Request for Comments. RFCs are documents that describe various Internet protocols and implementation procedures for the operating system and its applications. The RFC documents describe the setup of Internet protocols. For more information about RFCs, see http://www.ietf.org/rfc.html.
Several Protocols in the TCP/IP Protocol Family #
- TCP
Transmission Control Protocol: a connection-oriented secure protocol. The data to transmit is first sent by the application as a stream of data and converted into the appropriate format by the operating system. The data arrives at the respective application on the destination host in the original data stream format it was initially sent. TCP determines whether any data has been lost or jumbled during the transmission. TCP is implemented wherever the data sequence matters.
- UDP
User Datagram Protocol: a connectionless, insecure protocol. The data to transmit is sent in the form of packets generated by the application. The order in which the data arrives at the recipient is not guaranteed and data loss is possible. UDP is suitable for record-oriented applications. It features a smaller latency period than TCP.
- ICMP
Internet Control Message Protocol: This is not a protocol for the end user, but a special control protocol that issues error reports and can control the behavior of machines participating in TCP/IP data transfer. In addition, it provides a special echo mode that can be viewed using the program ping.
- IGMP
Internet Group Management Protocol: This protocol controls machine behavior when implementing IP multicast.
As shown in Figure 13.1, “Simplified Layer Model for TCP/IP”, data exchange takes place in different layers. The actual network layer is the insecure data transfer via IP (Internet protocol). On top of IP, TCP (transmission control protocol) guarantees, to a certain extent, security of the data transfer. The IP layer is supported by the underlying hardware-dependent protocol, such as Ethernet.
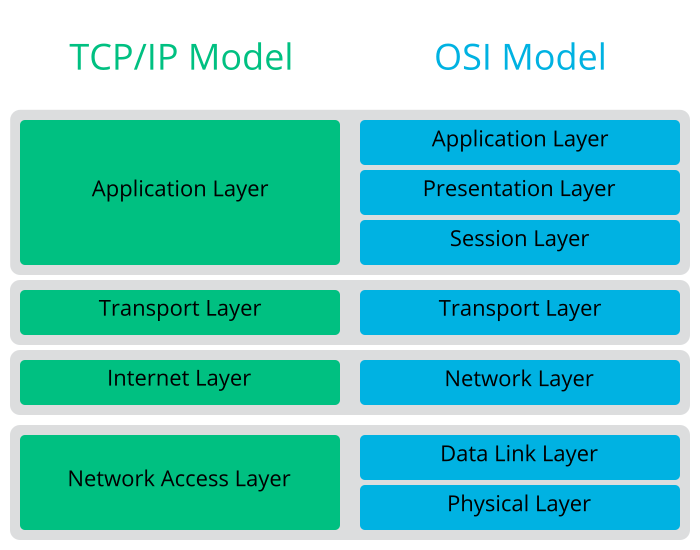
Figure 13.1: Simplified Layer Model for TCP/IP #
The diagram provides one or two examples for each layer. The layers are ordered according to abstraction levels. The lowest layer is very close to the hardware. The uppermost layer, however, is almost a complete abstraction from the hardware. Every layer has its own special function. The special functions of each layer are mostly implicit in their description. The data link and physical layers represent the physical network used, such as Ethernet.
Almost all hardware protocols work on a packet-oriented basis. The data to transmit is collected into packets (it cannot be sent all at once). The maximum size of a TCP/IP packet is approximately 64 KB. Packets are normally quite smaller, as the network hardware can be a limiting factor. The maximum size of a data packet on an Ethernet is about fifteen hundred bytes. The size of a TCP/IP packet is limited to this amount when the data is sent over an Ethernet. If more data is transferred, more data packets need to be sent by the operating system.
For the layers to serve their designated functions, additional information regarding each layer must be saved in the data packet. This takes place in the header of the packet. Every layer attaches a small block of data, called the protocol header, to the front of each emerging packet. A sample TCP/IP data packet traveling over an Ethernet cable is illustrated in Figure 13.2, “TCP/IP Ethernet Packet”. The proof sum is located at the end of the packet, not at the beginning. This simplifies things for the network hardware.

Figure 13.2: TCP/IP Ethernet Packet #
When an application sends data over the network, the data passes through each layer, all implemented in the Linux kernel except the physical layer. Each layer is responsible for preparing the data so it can be passed to the next layer. The lowest layer is ultimately responsible for sending the data. The entire procedure is reversed when data is received. Like the layers of an onion, in each layer the protocol headers are removed from the transported data. Finally, the transport layer is responsible for making the data available for use by the applications at the destination. In this manner, one layer only communicates with the layer directly above or below it. For applications, it is irrelevant whether data is transmitted via a 100 Mbit/s FDDI network or via a 56-Kbit/s modem line. Likewise, it is irrelevant for the data line which kind of data is transmitted, as long as packets are in the correct format.
13.1 IP Addresses and Routing #Edit source
The discussion in this section is limited to IPv4 networks. For information about IPv6 protocol, the successor to IPv4, refer to Section 13.2, “IPv6—The Next Generation Internet”.
13.1.1 IP Addresses #Edit source
Every computer on the Internet has a unique 32-bit address. These 32 bits (or 4 bytes) are normally written as illustrated in the second row in Example 13.1, “Writing IP Addresses”.
Example 13.1: Writing IP Addresses #
IP Address (binary): 11000000 10101000 00000000 00010100 IP Address (decimal): 192. 168. 0. 20
In decimal form, the four bytes are written in the decimal number system, separated by periods. The IP address is assigned to a host or a network interface. It can be used only once throughout the world. There are exceptions to this rule, but these are not relevant to the following passages.
The points in IP addresses indicate the hierarchical system. Until the 1990s, IP addresses were strictly categorized in classes. However, this system proved too inflexible and was discontinued. Now, classless routing (CIDR, classless interdomain routing) is used.
13.1.2 Netmasks and Routing #Edit source
Netmasks are used to define the address range of a subnet. If two hosts are in the same subnet, they can reach each other directly. If they are not in the same subnet, they need the address of a gateway that handles all the traffic for the subnet. To check if two IP addresses are in the same subnet, simply “AND” both addresses with the netmask. If the result is identical, both IP addresses are in the same local network. If there are differences, the remote IP address, and thus the remote interface, can only be reached over a gateway.
To understand how the netmask works, look at
Example 13.2, “Linking IP Addresses to the Netmask”. The netmask consists of 32 bits
that identify how much of an IP address belongs to the network. All those
bits that are 1 mark the corresponding bit in the IP
address as belonging to the network. All bits that are 0
mark bits inside the subnet. This means that the more bits are
1, the smaller the subnet is. Because the netmask always
consists of several successive 1 bits, it is also
possible to count the number of bits in the netmask. In
Example 13.2, “Linking IP Addresses to the Netmask” the first net with 24 bits could
also be written as 192.168.0.0/24.
Example 13.2: Linking IP Addresses to the Netmask #
IP address (192.168.0.20): 11000000 10101000 00000000 00010100 Netmask (255.255.255.0): 11111111 11111111 11111111 00000000 --------------------------------------------------------------- Result of the link: 11000000 10101000 00000000 00000000 In the decimal system: 192. 168. 0. 0 IP address (213.95.15.200): 11010101 10111111 00001111 11001000 Netmask (255.255.255.0): 11111111 11111111 11111111 00000000 --------------------------------------------------------------- Result of the link: 11010101 10111111 00001111 00000000 In the decimal system: 213. 95. 15. 0
To give another example: all machines connected with the same Ethernet cable are usually located in the same subnet and are directly accessible. Even when the subnet is physically divided by switches or bridges, these hosts can still be reached directly.
IP addresses outside the local subnet can only be reached if a gateway is configured for the target network. In the most common case, there is only one gateway that handles all traffic that is external. However, it is also possible to configure several gateways for different subnets.
If a gateway has been configured, all external IP packets are sent to the appropriate gateway. This gateway then attempts to forward the packets in the same manner—from host to host—until it reaches the destination host or the packet's TTL (time to live) expires.
Specific Addresses #
- Base Network Address
This is the netmask AND any address in the network, as shown in Example 13.2, “Linking IP Addresses to the Netmask” under
Result. This address cannot be assigned to any hosts.- Broadcast Address
This could be paraphrased as: “Access all hosts in this subnet.” To generate this, the netmask is inverted in binary form and linked to the base network address with a logical OR. The above example therefore results in 192.168.0.255. This address cannot be assigned to any hosts.
- Local Host
The address
127.0.0.1is assigned to the “loopback device” on each host. A connection can be set up to your own machine with this address and with all addresses from the complete127.0.0.0/8loopback network as defined with IPv4. With IPv6 there is only one loopback address (::1).
Because IP addresses must be unique all over the world, you cannot select random addresses. There are three address domains to use if you want to set up a private IP-based network. These cannot get any connection from the rest of the Internet, because they cannot be transmitted over the Internet. These address domains are specified in RFC 1597 and listed in Table 13.1, “Private IP Address Domains”.
Table 13.1: Private IP Address Domains #
|
Network/Netmask |
Domain |
|---|---|
|
|
|
|
|
|
|
|
|
13.2 IPv6—The Next Generation Internet #Edit source
Because of the emergence of the World Wide Web (WWW), the Internet has experienced explosive growth, with an increasing number of computers communicating via TCP/IP in the past fifteen years. Since Tim Berners-Lee at CERN (http://public.web.cern.ch) invented the WWW in 1990, the number of Internet hosts has grown from a few thousand to about a hundred million.
As mentioned, an IPv4 address consists of only 32 bits. Also, quite a few IP addresses are lost—they cannot be used because of the way in which networks are organized. The number of addresses available in your subnet is two to the power of the number of bits, minus two. A subnet has, for example, 2, 6, or 14 addresses available. To connect 128 hosts to the Internet, for example, you need a subnet with 256 IP addresses, from which only 254 are usable, because two IP addresses are needed for the structure of the subnet itself: the broadcast and the base network address.
Under the current IPv4 protocol, DHCP or NAT (network address translation) are the typical mechanisms used to circumvent the potential address shortage. Combined with the convention to keep private and public address spaces separate, these methods can certainly mitigate the shortage. The problem with them lies in their configuration, which is a chore to set up and a burden to maintain. To set up a host in an IPv4 network, you need several address items, such as the host's own IP address, the subnetmask, the gateway address and maybe a name server address. All these items need to be known and cannot be derived from somewhere else.
With IPv6, both the address shortage and the complicated configuration should be a thing of the past. The following sections tell more about the improvements and benefits brought by IPv6 and about the transition from the old protocol to the new one.
13.2.1 Advantages #Edit source
The most important and most visible improvement brought by the new protocol is the enormous expansion of the available address space. An IPv6 address is made up of 128 bit values instead of the traditional 32 bits. This provides for as many as several quadrillion IP addresses.
However, IPv6 addresses are not only different from their predecessors with regard to their length. They also have a different internal structure that may contain more specific information about the systems and the networks to which they belong. More details about this are found in Section 13.2.2, “Address Types and Structure”.
The following is a list of other advantages of the new protocol:
- Autoconfiguration
IPv6 makes the network “plug and play” capable, which means that a newly set up system integrates into the (local) network without any manual configuration. The new host uses its automatic configuration mechanism to derive its own address from the information made available by the neighboring routers, relying on a protocol called the neighbor discovery (ND) protocol. This method does not require any intervention on the administrator's part and there is no need to maintain a central server for address allocation—an additional advantage over IPv4, where automatic address allocation requires a DHCP server.
Nevertheless if a router is connected to a switch, the router should send periodic advertisements with flags telling the hosts of a network how they should interact with each other. For more information, see RFC 2462 and the
radvd.conf(5)man page, and RFC 3315.- Mobility
IPv6 makes it possible to assign several addresses to one network interface at the same time. This allows users to access several networks easily, something that could be compared with the international roaming services offered by mobile phone companies. When you take your mobile phone abroad, the phone automatically logs in to a foreign service when it enters the corresponding area, so you can be reached under the same number everywhere and can place an outgoing call, as you would in your home area.
- Secure Communication
With IPv4, network security is an add-on function. IPv6 includes IPsec as one of its core features, allowing systems to communicate over a secure tunnel to avoid eavesdropping by outsiders on the Internet.
- Backward Compatibility
Realistically, it would be impossible to switch the entire Internet from IPv4 to IPv6 at one time. Therefore, it is crucial that both protocols can coexist not only on the Internet, but also on one system. This is ensured by compatible addresses (IPv4 addresses can easily be translated into IPv6 addresses) and by using several tunnels. See Section 13.2.3, “Coexistence of IPv4 and IPv6”. Also, systems can rely on a dual stack IP technique to support both protocols at the same time, meaning that they have two network stacks that are completely separate, such that there is no interference between the two protocol versions.
- Custom Tailored Services through Multicasting
With IPv4, some services, such as SMB, need to broadcast their packets to all hosts in the local network. IPv6 allows a much more fine-grained approach by enabling servers to address hosts through multicasting, that is by addressing several hosts as parts of a group. This is different from addressing all hosts through broadcasting or each host individually through unicasting. Which hosts are addressed as a group may depend on the concrete application. There are some predefined groups to address all name servers (the all name servers multicast group), for example, or all routers (the all routers multicast group).
13.2.2 Address Types and Structure #Edit source
As mentioned, the current IP protocol has two major limitations: there is an increasing shortage of IP addresses, and configuring the network and maintaining the routing tables is becoming a more complex and burdensome task. IPv6 solves the first problem by expanding the address space to 128 bits. The second one is mitigated by introducing a hierarchical address structure combined with sophisticated techniques to allocate network addresses, and multihoming (the ability to assign several addresses to one device, giving access to several networks).
When dealing with IPv6, it is useful to know about three different types of addresses:
- Unicast
Addresses of this type are associated with exactly one network interface. Packets with such an address are delivered to only one destination. Accordingly, unicast addresses are used to transfer packets to individual hosts on the local network or the Internet.
- Multicast
Addresses of this type relate to a group of network interfaces. Packets with such an address are delivered to all destinations that belong to the group. Multicast addresses are mainly used by certain network services to communicate with certain groups of hosts in a well-directed manner.
- Anycast
Addresses of this type are related to a group of interfaces. Packets with such an address are delivered to the member of the group that is closest to the sender, according to the principles of the underlying routing protocol. Anycast addresses are used to make it easier for hosts to find out about servers offering certain services in the given network area. All servers of the same type have the same anycast address. Whenever a host requests a service, it receives a reply from the server with the closest location, as determined by the routing protocol. If this server should fail for some reason, the protocol automatically selects the second closest server, then the third one, and so forth.
An IPv6 address is made up of eight four-digit fields, each representing 16
bits, written in hexadecimal notation. They are separated by colons
(:). Any leading zero bytes within a given field may be
dropped, but zeros within the field or at its end may not. Another
convention is that more than four consecutive zero bytes may be collapsed
into a double colon. However, only one such :: is
allowed per address. This kind of shorthand notation is shown in
Example 13.3, “Sample IPv6 Address”, where all three lines represent the
same address.
Example 13.3: Sample IPv6 Address #
fe80 : 0000 : 0000 : 0000 : 0000 : 10 : 1000 : 1a4 fe80 : 0 : 0 : 0 : 0 : 10 : 1000 : 1a4 fe80 : : 10 : 1000 : 1a4
Each part of an IPv6 address has a defined function. The first bytes form
the prefix and specify the type of address. The center part is the network
portion of the address, but it may be unused. The end of the address forms
the host part. With IPv6, the netmask is defined by indicating the length
of the prefix after a slash at the end of the address. An address, as shown
in Example 13.4, “IPv6 Address Specifying the Prefix Length”, contains the information that
the first 64 bits form the network part of the address and the last 64 form
its host part. In other words, the 64 means that the
netmask is filled with 64 1-bit values from the left. As with IPv4, the IP
address is combined with AND with the values from the netmask to determine
whether the host is located in the same subnet or in another one.
Example 13.4: IPv6 Address Specifying the Prefix Length #
fe80::10:1000:1a4/64
IPv6 knows about several predefined types of prefixes. Some are shown in Various IPv6 Prefixes.
Various IPv6 Prefixes #
00IPv4 addresses and IPv4 over IPv6 compatibility addresses. These are used to maintain compatibility with IPv4. Their use still requires a router able to translate IPv6 packets into IPv4 packets. Several special addresses, such as the one for the loopback device, have this prefix as well.
2or3as the first digitAggregatable global unicast addresses. As is the case with IPv4, an interface can be assigned to form part of a certain subnet. Currently, there are the following address spaces:
2001::/16(production quality address space) and2002::/16(6to4 address space).fe80::/10Link-local addresses. Addresses with this prefix should not be routed and should therefore only be reachable from within the same subnet.
fec0::/10Site-local addresses. These may be routed, but only within the network of the organization to which they belong. In effect, they are the IPv6 equivalent of the current private network address space, such as
10.x.x.x.ffThese are multicast addresses.
A unicast address consists of three basic components:
- Public Topology
The first part (which also contains one of the prefixes mentioned above) is used to route packets through the public Internet. It includes information about the company or institution that provides the Internet access.
- Site Topology
The second part contains routing information about the subnet to which to deliver the packet.
- Interface ID
The third part identifies the interface to which to deliver the packet. This also allows for the MAC to form part of the address. Given that the MAC is a globally unique, fixed identifier coded into the device by the hardware maker, the configuration procedure is substantially simplified. In fact, the first 64 address bits are consolidated to form the
EUI-64token, with the last 48 bits taken from the MAC, and the remaining 24 bits containing special information about the token type. This also makes it possible to assign anEUI-64token to interfaces that do not have a MAC, such as those based on PPP.
On top of this basic structure, IPv6 distinguishes between five different types of unicast addresses:
::(unspecified)This address is used by the host as its source address when the interface is initialized for the first time (at which point, the address cannot yet be determined by other means).
::1(loopback)The address of the loopback device.
- IPv4 Compatible Addresses
The IPv6 address is formed by the IPv4 address and a prefix consisting of 96 zero bits. This type of compatibility address is used for tunneling (see Section 13.2.3, “Coexistence of IPv4 and IPv6”) to allow IPv4 and IPv6 hosts to communicate with others operating in a pure IPv4 environment.
- IPv4 Addresses Mapped to IPv6
This type of address specifies a pure IPv4 address in IPv6 notation.
- Local Addresses
There are two address types for local use:
- link-local
This type of address can only be used in the local subnet. Packets with a source or target address of this type should not be routed to the Internet or other subnets. These addresses contain a special prefix (
fe80::/10) and the interface ID of the network card, with the middle part consisting of zero bytes. Addresses of this type are used during automatic configuration to communicate with other hosts belonging to the same subnet.- site-local
Packets with this type of address may be routed to other subnets, but not to the wider Internet—they must remain inside the organization's own network. Such addresses are used for intranets and are an equivalent of the private address space defined by IPv4. They contain a special prefix (
fec0::/10), the interface ID, and a 16 bit field specifying the subnet ID. Again, the rest is filled with zero bytes.
As a completely new feature introduced with IPv6, each network interface normally gets several IP addresses, with the advantage that several networks can be accessed through the same interface. One of these networks can be configured completely automatically using the MAC and a known prefix with the result that all hosts on the local network can be reached when IPv6 is enabled (using the link-local address). With the MAC forming part of it, any IP address used in the world is unique. The only variable parts of the address are those specifying the site topology and the public topology, depending on the actual network in which the host is currently operating.
For a host to go back and forth between different networks, it needs at least two addresses. One of them, the home address, not only contains the interface ID but also an identifier of the home network to which it normally belongs (and the corresponding prefix). The home address is a static address and, as such, it does not normally change. Still, all packets destined to the mobile host can be delivered to it, regardless of whether it operates in the home network or somewhere outside. This is made possible by the completely new features introduced with IPv6, such as stateless autoconfiguration and neighbor discovery. In addition to its home address, a mobile host gets one or more additional addresses that belong to the foreign networks where it is roaming. These are called care-of addresses. The home network has a facility that forwards any packets destined to the host when it is roaming outside. In an IPv6 environment, this task is performed by the home agent, which takes all packets destined to the home address and relays them through a tunnel. On the other hand, those packets destined to the care-of address are directly transferred to the mobile host without any special detours.
13.2.3 Coexistence of IPv4 and IPv6 #Edit source
The migration of all hosts connected to the Internet from IPv4 to IPv6 is a gradual process. Both protocols will coexist for some time to come. The coexistence on one system is guaranteed where there is a dual stack implementation of both protocols. That still leaves the question of how an IPv6 enabled host should communicate with an IPv4 host and how IPv6 packets should be transported by the current networks, which are predominantly IPv4-based. The best solutions offer tunneling and compatibility addresses (see Section 13.2.2, “Address Types and Structure”).
IPv6 hosts that are more or less isolated in the (worldwide) IPv4 network can communicate through tunnels: IPv6 packets are encapsulated as IPv4 packets to move them across an IPv4 network. Such a connection between two IPv4 hosts is called a tunnel. To achieve this, packets must include the IPv6 destination address (or the corresponding prefix) and the IPv4 address of the remote host at the receiving end of the tunnel. A basic tunnel can be configured manually according to an agreement between the hosts' administrators. This is also called static tunneling.
However, the configuration and maintenance of static tunnels is often too labor-intensive to use them for daily communication needs. Therefore, IPv6 provides for three different methods of dynamic tunneling:
- 6over4
IPv6 packets are automatically encapsulated as IPv4 packets and sent over an IPv4 network capable of multicasting. IPv6 is tricked into seeing the whole network (Internet) as a huge local area network (LAN). This makes it possible to determine the receiving end of the IPv4 tunnel automatically. However, this method does not scale very well and is also hampered because IP multicasting is far from widespread on the Internet. Therefore, it only provides a solution for smaller corporate or institutional networks where multicasting can be enabled. The specifications for this method are laid down in RFC 2529.
- 6to4
With this method, IPv4 addresses are automatically generated from IPv6 addresses, enabling isolated IPv6 hosts to communicate over an IPv4 network. However, several problems have been reported regarding the communication between those isolated IPv6 hosts and the Internet. The method is described in RFC 3056.
- IPv6 Tunnel Broker
This method relies on special servers that provide dedicated tunnels for IPv6 hosts. It is described in RFC 3053.
13.2.4 Configuring IPv6 #Edit source
To configure IPv6, you normally do not need to make any changes on the
individual workstations. IPv6 is enabled by default. To disable or enable
IPv6 on an installed system, use the YaST module. On the tab,
select or deselect the option as necessary.
To enable it temporarily until the next reboot, enter
modprobe -i ipv6 as
root. It is impossible to unload
the IPv6 module after it has been loaded.
Because of the autoconfiguration concept of IPv6, the network card is assigned an address in the link-local network. Normally, no routing table management takes place on a workstation. The network routers can be queried by the workstation, using the router advertisement protocol, for what prefix and gateways should be implemented. The radvd program can be used to set up an IPv6 router. This program informs the workstations which prefix to use for the IPv6 addresses and which routers. Alternatively, use zebra/quagga for automatic configuration of both addresses and routing.
For information about how to set up various types of tunnels using the
/etc/sysconfig/network files, see the man page of
ifcfg-tunnel (man ifcfg-tunnel).
13.2.5 For More Information #Edit source
The above overview does not cover the topic of IPv6 comprehensively. For a more in-depth look at the new protocol, refer to the following online documentation and books:
- http://www.ipv6.org/
The starting point for everything about IPv6.
- http://www.ipv6day.org
All information needed to start your own IPv6 network.
- http://www.ipv6-to-standard.org/
The list of IPv6-enabled products.
- http://www.bieringer.de/linux/IPv6/
Here, find the Linux IPv6-HOWTO and many links related to the topic.
- RFC 2460
The fundamental RFC about IPv6.
- IPv6 Essentials
A book describing all the important aspects of the topic is IPv6 Essentials by Silvia Hagen (ISBN 0-596-00125-8).
13.3 Name Resolution #Edit source
DNS assists in assigning an IP address to one or more names and assigning a name to an IP address. In Linux, this conversion is usually carried out by a special type of software known as bind. The machine that takes care of this conversion is called a name server. The names make up a hierarchical system in which each name component is separated by a period. The name hierarchy is, however, independent of the IP address hierarchy described above.
Consider a complete name, such as
jupiter.example.com, written in the
format hostname.domain. A full
name, called a fully qualified domain name (FQDN),
consists of a host name and a domain name
(example.com). The latter
also includes the top level domain or TLD
(com).
TLD assignment has become quite confusing for historical reasons.
Traditionally, three-letter domain names are used in the USA. In the rest of
the world, the two-letter ISO national codes are the standard. In addition
to that, longer TLDs were introduced in 2000 that represent certain spheres
of activity (for example, .info,
.name,
.museum).
In the early days of the Internet (before 1990), the file
/etc/hosts was used to store the names of all the
machines represented over the Internet. This quickly proved to be
impractical in the face of the rapidly growing number of computers connected
to the Internet. For this reason, a decentralized database was developed to
store the host names in a widely distributed manner. This database, similar
to the name server, does not have the data pertaining to all hosts in the
Internet readily available, but can dispatch requests to other name servers.
The top of the hierarchy is occupied by root name servers. These root name servers manage the top level domains and are run by the Network Information Center (NIC). Each root name server knows about the name servers responsible for a given top level domain. Information about top level domain NICs is available at http://www.internic.net.
DNS can do more than resolve host names. The name server also knows which host is receiving e-mails for an entire domain—the mail exchanger (MX).
For your machine to resolve an IP address, it must know about at least one name server and its IP address. Easily specify such a name server using YaST. The configuration of name server access with openSUSE® Leap is described in Section 13.4.1.4, “Configuring Host Name and DNS”. Setting up your own name server is described in Chapter 19, The Domain Name System.
The protocol whois is closely related to DNS. With this
program, quickly find out who is responsible for a given domain.
Note: MDNS and .local Domain Names
The .local top level domain is treated as link-local
domain by the resolver. DNS requests are send as multicast DNS requests
instead of normal DNS requests. If you already use the
.local domain in your name server configuration, you
must switch this option off in /etc/host.conf. For
more information, see the host.conf manual page.
To switch off MDNS during installation, use
nomdns=1 as a boot parameter.
For more information on multicast DNS, see http://www.multicastdns.org.
13.4 Configuring a Network Connection with YaST #Edit source
There are many supported networking types on Linux. Most of them use different device names and the configuration files are spread over several locations in the file system. For a detailed overview of the aspects of manual network configuration, see Section 13.6, “Configuring a Network Connection Manually”.
All network interfaces with link up (with a network cable connected) are automatically configured. Additional hardware can be configured any time on the installed system. The following sections describe the network configuration for all types of network connections supported by openSUSE Leap.
13.4.1 Configuring the Network Card with YaST #Edit source
To configure your Ethernet or Wi-Fi/Bluetooth card in YaST, select › . After starting the module, YaST displays the dialog with four tabs: , , and .
The tab allows you to set general networking options such as the network setup method, IPv6, and general DHCP options. For more information, see Section 13.4.1.1, “Configuring Global Networking Options”.
The tab contains information about installed network interfaces and configurations. Any properly detected network card is listed with its name. You can manually configure new cards, remove or change their configuration in this dialog. To manually configure a card that was not automatically detected, see Section 13.4.1.3, “Configuring an Undetected Network Card”. To change the configuration of an already configured card, see Section 13.4.1.2, “Changing the Configuration of a Network Card”.
The tab allows to set the host name of the machine and name the servers to be used. For more information, see Section 13.4.1.4, “Configuring Host Name and DNS”.
The tab is used for the configuration of routing. See Section 13.4.1.5, “Configuring Routing” for more information.
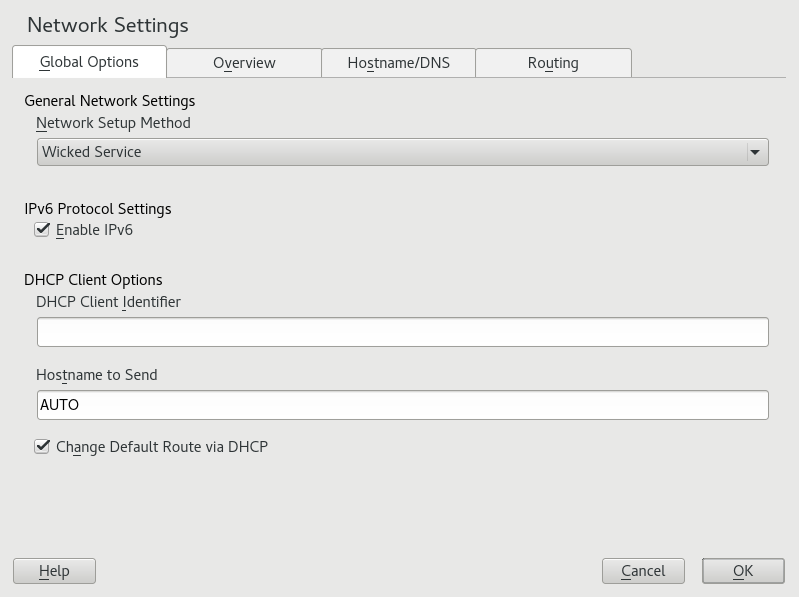
Figure 13.3: Configuring Network Settings #
13.4.1.1 Configuring Global Networking Options #Edit source
The tab of the YaST module allows you to set important global networking options, such as the use of NetworkManager, IPv6 and DHCP client options. These settings are applicable for all network interfaces.
In the choose the way network
connections are managed. If you want a NetworkManager desktop applet to manage
connections for all interfaces, choose .
NetworkManager is well suited for switching between multiple wired and wireless
networks. If you do not run a desktop environment, or if your computer is a
Xen server, virtual system, or provides network services such as DHCP or
DNS in your network, use the method. If
NetworkManager is used, nm-applet should be used to configure
network options and the ,
and tabs of the
module are disabled.
For more information on NetworkManager, see
Chapter 28, Using NetworkManager.
In the choose whether to use the IPv6 protocol. It is possible to use IPv6 together with IPv4. By default, IPv6 is enabled. However, in networks not using IPv6 protocol, response times can be faster with IPv6 protocol disabled. To disable IPv6, deactivate . If IPv6 is disabled, the kernel no longer loads the IPv6 module automatically. This setting will be applied after reboot.
In the configure options for the DHCP client. The must be different for each DHCP client on a single network. If left empty, it defaults to the hardware address of the network interface. However, if you are running several virtual machines using the same network interface and, therefore, the same hardware address, specify a unique free-form identifier here.
The specifies a string used for the
host name option field when the DHCP client sends messages to DHCP server.
Some DHCP servers update name server zones (forward and reverse records)
according to this host name (Dynamic DNS). Also, some DHCP servers require
the option field to contain a specific
string in the DHCP messages from clients. Leave AUTO to
send the current host name (that is the one defined in
/etc/HOSTNAME). Make the option field empty for not
sending any host name.
If you do not want to change the default route according to the information from DHCP, deactivate .
13.4.1.2 Changing the Configuration of a Network Card #Edit source
To change the configuration of a network card, select a card from the list of the detected cards in › in YaST and click . The dialog appears in which to adjust the card configuration using the , and tabs.
13.4.1.2.1 Configuring IP Addresses #Edit source
You can set the IP address of the network card or the way its IP address is determined in the tab of the dialog. Both IPv4 and IPv6 addresses are supported. The network card can have (which is useful for bonding devices), a (IPv4 or IPv6) or a assigned via or or both.
If using , select whether to use (for IPv4), (for IPv6) or .
If possible, the first network card with link that is available during the installation is automatically configured to use automatic address setup via DHCP.
DHCP should also be used if you are using a DSL line but with no static IP assigned by the ISP (Internet Service Provider). If you decide to use DHCP, configure the details in in the tab of the dialog of the YaST network card configuration module. If you have a virtual host setup where different hosts communicate through the same interface, an is necessary to distinguish them.
DHCP is a good choice for client configuration but it is not ideal for server configuration. To set a static IP address, proceed as follows:
Select a card from the list of detected cards in the tab of the YaST network card configuration module and click .
In the tab, choose .
Enter the . Both IPv4 and IPv6 addresses can be used. Enter the network mask in . If the IPv6 address is used, use for prefix length in format
/64.Optionally, you can enter a fully qualified for this address, which will be written to the
/etc/hostsconfiguration file.Click .
To activate the configuration, click .
Note: Interface Activation and Link Detection
During activation of a network interface, wicked
checks for a carrier and only applies the IP configuration when a link
has been detected. If you need to apply the configuration regardless of
the link status (for example, when you want to test a service listening to a
certain address), you can skip link detection by adding the variable
LINK_REQUIRED=no to the configuration file of the
interface in /etc/sysconfig/network/ifcfg.
Additionally, you can use the variable
LINK_READY_WAIT=5 to
specify the timeout for waiting for a link in seconds.
For more information about the ifcfg-* configuration
files, refer to Section 13.6.2.5, “/etc/sysconfig/network/ifcfg-*” and
man 5 ifcfg.
If you use the static address, the name servers and default gateway are not configured automatically. To configure name servers, proceed as described in Section 13.4.1.4, “Configuring Host Name and DNS”. To configure a gateway, proceed as described in Section 13.4.1.5, “Configuring Routing”.
13.4.1.2.2 Configuring Multiple Addresses #Edit source
One network device can have multiple IP addresses.
Note: Aliases Are a Compatibility Feature
These so-called aliases or labels, respectively, work with IPv4 only.
With IPv6 they will be ignored. Using iproute2 network
interfaces can have one or more addresses.
Using YaST to set additional addresses for your network card, proceed as follows:
Select a card from the list of detected cards in the tab of the YaST dialog and click .
In the › tab, click .
Enter , , and . Do not include the interface name in the alias name.
To activate the configuration, confirm the settings.
13.4.1.2.3 Changing the Device Name and Udev Rules #Edit source
It is possible to change the device name of the network card when it is used. It is also possible to determine whether the network card should be identified by udev via its hardware (MAC) address or via the bus ID. The latter option is preferable in large servers to simplify hotplugging of cards. To set these options with YaST, proceed as follows:
Select a card from the list of detected cards in the tab of the YaST dialog and click .
Go to the tab. The current device name is shown in . Click .
Select whether udev should identify the card by its or . The current MAC address and bus ID of the card are shown in the dialog.
To change the device name, check the option and edit the name.
To activate the configuration, confirm the settings.
13.4.1.2.4 Changing Network Card Kernel Driver #Edit source
For some network cards, several kernel drivers may be available. If the card is already configured, YaST allows you to select a kernel driver to be used from a list of available suitable drivers. It is also possible to specify options for the kernel driver. To set these options with YaST, proceed as follows:
Select a card from the list of detected cards in the tab of the YaST Network Settings module and click .
Go to the tab.
Select the kernel driver to be used in . Enter any options for the selected driver in in the form
==VALUE. If more options are used, they should be space-separated.To activate the configuration, confirm the settings.
13.4.1.2.5 Activating the Network Device #Edit source
If you use the method with wicked, you can configure
your device to either start during boot, on cable connection, on card
detection, manually, or never. To change device start-up, proceed as
follows:
In YaST select a card from the list of detected cards in › and click .
In the tab, select the desired entry from .
Choose to start the device during the system boot. With , the interface is watched for any existing physical connection. With , the interface is set when available. It is similar to the option, and only differs in that no error occurs if the interface is not present at boot time. Choose to control the interface manually with
ifup. Choose to not start the device. The is similar to , but the interface does not shut down with thesystemctl stop networkcommand; thenetworkservice also cares about thewickedservice ifwickedis active. Use this if you use an NFS or iSCSI root file system.To activate the configuration, confirm the settings.
Tip: NFS as a Root File System
On (diskless) systems where the root partition is mounted via network as an NFS share, you need to be careful when configuring the network device with which the NFS share is accessible.
When shutting down or rebooting the system, the default processing order is to turn off network connections, then unmount the root partition. With NFS root, this order causes problems as the root partition cannot be cleanly unmounted as the network connection to the NFS share is already not activated. To prevent the system from deactivating the relevant network device, open the network device configuration tab as described in Section 13.4.1.2.5, “Activating the Network Device” and choose in the pane.
13.4.1.2.6 Setting Up Maximum Transfer Unit Size #Edit source
You can set a maximum transmission unit (MTU) for the interface. MTU refers to the largest allowed packet size in bytes. A higher MTU brings higher bandwidth efficiency. However, large packets can block up a slow interface for some time, increasing the lag for further packets.
In YaST select a card from the list of detected cards in › and click .
In the tab, select the desired entry from the list.
To activate the configuration, confirm the settings.
13.4.1.2.7 PCIe Multifunction Devices #Edit source
Multifunction devices that support LAN, iSCSI, and FCoE are supported.
The YaST FCoE client (yast2 fcoe-client) shows the
private flags in additional columns to allow the user to select the device
meant for FCoE. The YaST network module (yast2 lan)
excludes “storage only devices” for network configuration.
13.4.1.2.8 Infiniband Configuration for IP-over-InfiniBand (IPoIB) #Edit source
In YaST select the InfiniBand device in › and click .
In the tab, select one of the (IPoIB) modes: (default) or .
To activate the configuration, confirm the settings.
For more information about InfiniBand, see
/usr/src/linux/Documentation/infiniband/ipoib.txt.
13.4.1.2.9 Configuring the Firewall #Edit source
Without having to perform the detailed firewall setup as described in
Book “Security Guide”, Chapter 17 “Masquerading and Firewalls”, Section 17.4 “firewalld”, you can determine the
basic firewall configuration for your device as part of the device setup.
Proceed as follows:
Open the YaST › module. In the tab, select a card from the list of detected cards and click .
Enter the tab of the dialog.
Determine the to which your interface should be assigned. The following options are available:
- Firewall Disabled
This option is available only if the firewall is disabled and the firewall does not run. Only use this option if your machine is part of a greater network that is protected by an outer firewall.
- Automatically Assign Zone
This option is available only if the firewall is enabled. The firewall is running and the interface is automatically assigned to a firewall zone. The zone which contains the keyword
anyor the external zone will be used for such an interface.- Internal Zone (Unprotected)
The firewall is running, but does not enforce any rules to protect this interface. Use this option if your machine is part of a greater network that is protected by an outer firewall. It is also useful for the interfaces connected to the internal network, when the machine has more network interfaces.
- Demilitarized Zone
A demilitarized zone is an additional line of defense in front of an internal network and the (hostile) Internet. Hosts assigned to this zone can be reached from the internal network and from the Internet, but cannot access the internal network.
- External Zone
The firewall is running on this interface and fully protects it against other—presumably hostile—network traffic. This is the default option.
To activate the configuration, confirm the settings.
13.4.1.3 Configuring an Undetected Network Card #Edit source
If a network card is not detected correctly, the card is not included in the list of detected cards. If you are sure that your system includes a driver for your card, you can configure it manually. You can also configure special network device types, such as bridge, bond, TUN or TAP. To configure an undetected network card (or a special device) proceed as follows:
In the › › dialog in YaST click .
In the dialog, set the of the interface from the available options and . If the network card is a USB device, activate the respective check box and exit this dialog with . Otherwise, you can define the kernel to be used for the card and its , if necessary.
In , you can set
ethtooloptions used byifupfor the interface. For information about available options, see theethtoolmanual page.If the option string starts with a
-(for example,-K INTERFACE_NAME rx on), the second word in the string is replaced with the current interface name. Otherwise (for example,autoneg off speed 10)ifupadds-s INTERFACE_NAMEto the beginning.Click .
Configure any needed options, such as the IP address, device activation or firewall zone for the interface in the , , and tabs. For more information about the configuration options, see Section 13.4.1.2, “Changing the Configuration of a Network Card”.
If you selected as the device type of the interface, configure the wireless connection in the next dialog.
To activate the new network configuration, confirm the settings.
13.4.1.4 Configuring Host Name and DNS #Edit source
If you did not change the network configuration during installation and the Ethernet card was already available, a host name was automatically generated for your computer and DHCP was activated. The same applies to the name service information your host needs to integrate into a network environment. If DHCP is used for network address setup, the list of domain name servers is automatically filled with the appropriate data. If a static setup is preferred, set these values manually.
To change the name of your computer and adjust the name server search list, proceed as follows:
Go to the › tab in the module in YaST.
Enter the . Note that the host name is global and applies to all network interfaces.
If you are using DHCP to get an IP address, the host name of your computer will be automatically set by the DHCP server. You should disable this behavior if you connect to different networks, because they may assign different host names and changing the host name at runtime may confuse the graphical desktop. To disable using DHCP to get an IP address deactivate .
associates your host name with
127.0.0.2(loopback) IP address in/etc/hosts. This is a useful option if you want to have the host name resolvable at all times, even without active network.In , select the way the DNS configuration (name servers, search list, the content of the
/run/netconfig/resolv.conffile) is modified.If the option is selected, the configuration is handled by the
netconfigscript which merges the data defined statically (with YaST or in the configuration files) with data obtained dynamically (from the DHCP client or NetworkManager). This default policy is usually sufficient.If the option is selected,
netconfigis not allowed to modify the/run/netconfig/resolv.conffile. However, this file can be edited manually.If the option is selected, a string defining the merge policy should be specified. The string consists of a comma-separated list of interface names to be considered a valid source of settings. Except for complete interface names, basic wild cards to match multiple interfaces are allowed, as well. For example,
eth* ppp?will first target all eth and then all ppp0-ppp9 interfaces. There are two special policy values that indicate how to apply the static settings defined in the/etc/sysconfig/network/configfile:STATICThe static settings need to be merged together with the dynamic settings.
STATIC_FALLBACKThe static settings are used only when no dynamic configuration is available.
For more information, see the man page of
netconfig(8) (man 8 netconfig).Enter the and fill in the list. Name servers must be specified by IP addresses, such as 192.168.1.116, not by host names. Names specified in the tab are domain names used for resolving host names without a specified domain. If more than one is used, separate domains with commas or white space.
To activate the configuration, confirm the settings.
It is also possible to edit the host name using YaST from the command
line. The changes made by YaST take effect immediately (which is not the
case when editing the /etc/HOSTNAME file manually). To
change the host name, use the following command:
root # yast dns edit hostname=HOSTNAMETo change the name servers, use the following commands:
root #yast dns edit nameserver1=192.168.1.116root #yast dns edit nameserver2=192.168.1.117root #yast dns edit nameserver3=192.168.1.118
13.4.1.5 Configuring Routing #Edit source
To make your machine communicate with other machines and other networks, routing information must be given to make network traffic take the correct path. If DHCP is used, this information is automatically provided. If a static setup is used, this data must be added manually.
In YaST go to › .
Enter the IP address of the (IPv4 and IPv6 if necessary). The default gateway matches every possible destination, but if a routing table entry exists that matches the required address, this will be used instead of the default route via the Default Gateway.
More entries can be entered in the . Enter the network IP address, IP address and the . Select the through which the traffic to the defined network will be routed (the minus sign stands for any device). To omit any of these values, use the minus sign
-. To enter a default gateway into the table, usedefaultin the field.
Note: Route Prioritization
If more default routes are used, it is possible to specify the metric option to determine which route has a higher priority. To specify the metric option, enter
- metric NUMBERin . The route with the highest metric is used as default. If the network device is disconnected, its route will be removed and the next one will be used. However, the current kernel does not use metric in static routing, only routing daemons likemultipathddo.If the system is a router, enable and in the as needed.
To activate the configuration, confirm the settings.
13.5 NetworkManager #Edit source
NetworkManager is the ideal solution for laptops and other portable computers. With NetworkManager, you do not need to worry about configuring network interfaces and switching between networks when you are moving.
13.5.1 NetworkManager and wicked #Edit source
However, NetworkManager is not a suitable solution for all cases, so you can
still choose between the wicked controlled method for
managing network connections and NetworkManager. If you want to manage your
network connection with NetworkManager, enable NetworkManager in the YaST Network
Settings module as described in Section 28.2, “Enabling or Disabling NetworkManager” and
configure your network connections with NetworkManager. For a list of use cases
and a detailed description of how to configure and use NetworkManager, refer to
Chapter 28, Using NetworkManager.
Some differences between wicked and NetworkManager:
rootPrivilegesIf you use NetworkManager for network setup, you can easily switch, stop or start your network connection at any time from within your desktop environment using an applet. NetworkManager also makes it possible to change and configure wireless card connections without requiring
rootprivileges. For this reason, NetworkManager is the ideal solution for a mobile workstation.wickedalso provides some ways to switch, stop or start the connection with or without user intervention, like user-managed devices. However, this always requiresrootprivileges to change or configure a network device. This is often a problem for mobile computing, where it is not possible to preconfigure all the connection possibilities.- Types of Network Connections
Both
wickedand NetworkManager can handle network connections with a wireless network (with WEP, WPA-PSK, and WPA-Enterprise access) and wired networks using DHCP and static configuration. They also support connection through dial-up and VPN. With NetworkManager you can also connect a mobile broadband (3G) modem or set up a DSL connection, which is not possible with the traditional configuration.NetworkManager tries to keep your computer connected at all times using the best connection available. If the network cable is accidentally disconnected, it tries to reconnect. It can find the network with the best signal strength from the list of your wireless connections and automatically use it to connect. To get the same functionality with
wicked, more configuration effort is required.
13.5.2 NetworkManager Functionality and Configuration Files #Edit source
The individual network connection settings created with NetworkManager are
stored in configuration profiles. The system
connections configured with either NetworkManager or YaST are saved in
/etc/NetworkManager/system-connections/* or in
/etc/sysconfig/network/ifcfg-*. For GNOME, all
user-defined connections are stored in GConf.
In case no profile is configured, NetworkManager automatically creates one and
names it Auto $INTERFACE-NAME. That is made in an
attempt to work without any configuration for as many cases as (securely)
possible. If the automatically created profiles do not suit your needs,
use the network connection configuration dialogs provided by GNOME to
modify them as desired. For more information, see
Section 28.3, “Configuring Network Connections”.
13.5.3 Controlling and Locking Down NetworkManager Features #Edit source
On centrally administered machines, certain NetworkManager features can be controlled or disabled with PolKit, for example if a user is allowed to modify administrator defined connections or if a user is allowed to define their own network configurations. To view or change the respective NetworkManager policies, start the graphical tool for PolKit. In the tree on the left side, find them below the entry. For an introduction to PolKit and details on how to use it, refer to Book “Security Guide”, Chapter 10 “Authorization with PolKit”.
13.6 Configuring a Network Connection Manually #Edit source
Manual configuration of the network software should be the last alternative. Using YaST is recommended. However, this background information about the network configuration can also assist your work with YaST.
13.6.1 The wicked Network Configuration #Edit source
The tool and library called wicked provides a new
framework for network configuration.
One of the challenges with traditional network interface management is that different layers of network management get jumbled together into one single script, or at most two different scripts. These scripts interact with each other in a way that is not well defined. This leads to unpredictable issues, obscure constraints and conventions, etc. Several layers of special hacks for a variety of different scenarios increase the maintenance burden. Address configuration protocols are being used that are implemented via daemons like dhcpcd, which interact rather poorly with the rest of the infrastructure. Funky interface naming schemes that require heavy udev support are introduced to achieve persistent identification of interfaces.
The idea of wicked is to decompose the problem in several ways. None of them is entirely novel, but trying to put ideas from different projects together is hopefully going to create a better solution overall.
One approach is to use a client/server model. This allows wicked to define standardized facilities for things like address configuration that are well integrated with the overall framework. For example, using a specific address configuration, the administrator may request that an interface should be configured via DHCP or IPv4 zeroconf. In this case, the address configuration service simply obtains the lease from its server and passes it on to the wicked server process that installs the requested addresses and routes.
The other approach to decomposing the problem is to enforce the layering aspect. For any type of network interface, it is possible to define a dbus service that configures the network interface's device layer—a VLAN, a bridge, a bonding, or a paravirtualized device. Common functionality, such as address configuration, is implemented by joint services that are layered on top of these device specific services without having to implement them specifically.
The wicked framework implements these two aspects by using a variety of dbus services, which get attached to a network interface depending on its type. Here is a rough overview of the current object hierarchy in wicked.
Each network interface is represented via a child object of
/org/opensuse/Network/Interfaces. The name of the
child object is given by its ifindex. For example, the loopback interface,
which usually gets ifindex 1, is
/org/opensuse/Network/Interfaces/1, the first
Ethernet interface registered is
/org/opensuse/Network/Interfaces/2.
Each network interface has a “class” associated with it, which
is used to select the dbus interfaces it supports. By default, each network
interface is of class netif, and
wickedd will automatically
attach all interfaces compatible with this class. In the current
implementation, this includes the following interfaces:
- org.opensuse.Network.Interface
Generic network interface functions, such as taking the link up or down, assigning an MTU, etc.
- org.opensuse.Network.Addrconf.ipv4.dhcp, org.opensuse.Network.Addrconf.ipv6.dhcp, org.opensuse.Network.Addrconf.ipv4.auto
Address configuration services for DHCP, IPv4 zeroconf, etc.
Beyond this, network interfaces may require or offer special configuration
mechanisms. For an Ethernet device, for example, you should be able to
control the link speed, offloading of checksumming, etc. To achieve this,
Ethernet devices have a class of their own, called
netif-ethernet, which is a subclass of
netif. As a consequence, the dbus interfaces assigned to
an Ethernet interface include all the services listed above, plus the
org.opensuse.Network.Ethernet service available only to objects belonging to the netif-ethernet
class.
Similarly, there exist classes for interface types like bridges, VLANs, bonds, or infinibands.
How do you interact with an interface like VLAN (which is really a virtual network interface that
sits on top of an Ethernet device) that needs to be created
first? For this, wicked defines factory
interfaces, such as
org.opensuse.Network.VLAN.Factory. Such a factory
interface offers a single function that lets you create an interface of the
requested type. These factory interfaces are attached to the
/org/opensuse/Network/Interfaces list node.
13.6.1.1 wicked Architecture and Features #Edit source
The wicked service comprises several parts as depicted
in Figure 13.4, “wicked architecture”.
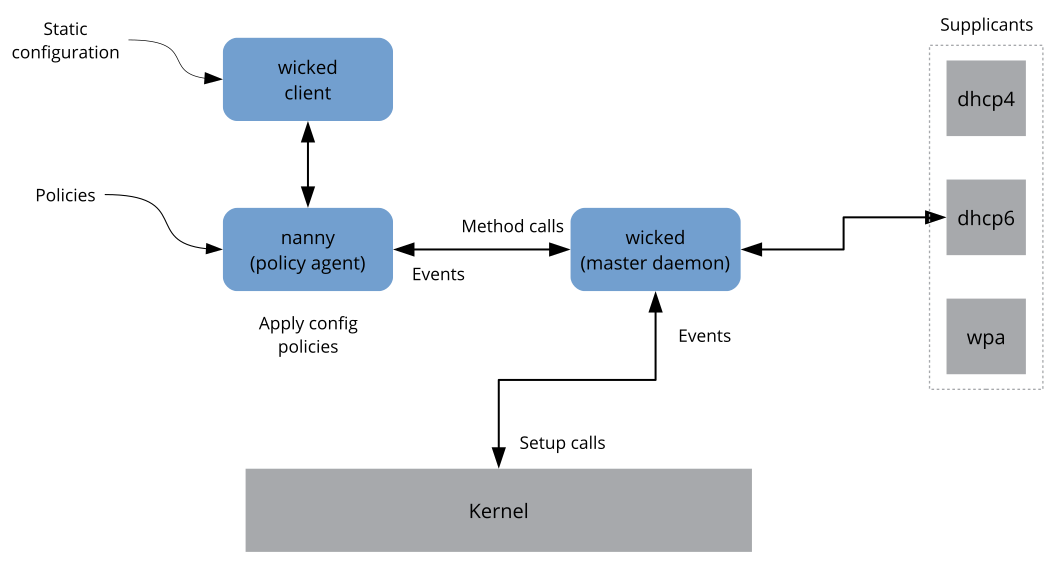
Figure 13.4: wicked architecture #
wicked currently supports the following:
Configuration file back-ends to parse SUSE style
/etc/sysconfig/networkfiles.An internal configuration back-end to represent network interface configuration in XML.
Bring up and shutdown of “normal” network interfaces such as Ethernet or InfiniBand, VLAN, bridge, bonds, tun, tap, dummy, macvlan, macvtap, hsi, qeth, iucv, and wireless (currently limited to one wpa-psk/eap network) devices.
A built-in DHCPv4 client and a built-in DHCPv6 client.
The nanny daemon (enabled by default) helps to automatically bring up configured interfaces when the device is available (interface hotplugging) and set up the IP configuration when a link (carrier) is detected. See Section 13.6.1.3, “Nanny” for more information.
wickedwas implemented as a group of DBus services that are integrated with systemd. So the usualsystemctlcommands will apply towicked.
13.6.1.2 Using wicked #Edit source
On openSUSE Leap, wicked runs by default on desktop or
server hardware. On mobile hardware NetworkManager runs by default. If you want to
check what is currently enabled and whether it is running, call:
systemctl status network
If wicked is enabled, you will see something along these
lines:
wicked.service - wicked managed network interfaces
Loaded: loaded (/usr/lib/systemd/system/wicked.service; enabled)
...
In case something different is running (for example, NetworkManager) and you want to
switch to wicked, first stop what is running and then
enable wicked:
systemctl is-active network && \ systemctl stop network systemctl enable --force wicked
This enables the wicked services, creates the
network.service to wicked.service
alias link, and starts the network at the next boot.
Starting the server process:
systemctl start wickedd
This starts wickedd (the main server) and associated
supplicants:
/usr/lib/wicked/bin/wickedd-auto4 --systemd --foreground /usr/lib/wicked/bin/wickedd-dhcp4 --systemd --foreground /usr/lib/wicked/bin/wickedd-dhcp6 --systemd --foreground /usr/sbin/wickedd --systemd --foreground /usr/sbin/wickedd-nanny --systemd --foreground
Then bringing up the network:
systemctl start wicked
Alternatively use the network.service alias:
systemctl start network
These commands are using the default or system configuration sources as
defined in /etc/wicked/client.xml.
To enable debugging, set WICKED_DEBUG in
/etc/sysconfig/network/config, for example:
WICKED_DEBUG="all"
Or, to omit some:
WICKED_DEBUG="all,-dbus,-objectmodel,-xpath,-xml"
Use the client utility to display interface information for all interfaces or the interface specified with IFNAME:
wicked show all wicked show IFNAME
In XML output:
wicked show-xml all wicked show-xml IFNAME
Bringing up one interface:
wicked ifup eth0 wicked ifup wlan0 ...
Because there is no configuration source specified, the wicked client
checks its default sources of configuration defined in
/etc/wicked/client.xml:
firmware:iSCSI Boot Firmware Table (iBFT)compat:ifcfgfiles—implemented for compatibility
Whatever wicked gets from those sources for a given
interface is applied. The intended order of importance is
firmware, then compat—this may
be changed in the future.
For more information, see the wicked man page.
13.6.1.3 Nanny #Edit source
Nanny is an event and policy driven daemon that is responsible for
asynchronous or unsolicited scenarios such as hotplugging devices. Thus the
nanny daemon helps with starting or restarting delayed or temporarily gone
devices. Nanny monitors device and link changes, and integrates new devices
defined by the current policy set. Nanny continues to set up even if
ifup already exited because of specified timeout
constraints.
By default, the nanny daemon is active on the system. It is enabled in the
/etc/wicked/common.xml configuration file:
<config> ... <use-nanny>true</use-nanny> </config>
This setting causes ifup and ifreload to apply a policy with the effective
configuration to the nanny daemon; then, nanny configures
wickedd and thus ensures
hotplug support. It waits in the background for events or changes (such as
new devices or carrier on).
13.6.1.4 Bringing Up Multiple Interfaces #Edit source
For bonds and bridges, it may make sense to define the entire device topology in one file (ifcfg-bondX), and bring it up in one go. wicked then can bring up the whole configuration if you specify the top level interface names (of the bridge or bond):
wicked ifup br0
This command automatically sets up the bridge and its dependencies in the appropriate order without the need to list the dependencies (ports, etc.) separately.
To bring up multiple interfaces in one command:
wicked ifup bond0 br0 br1 br2
Or also all interfaces:
wicked ifup all
13.6.1.5 Using Tunnels with Wicked #Edit source
When you need to use tunnels with Wicked, the TUNNEL_DEVICE
is used for this. It permits to specify an optional device name to bind
the tunnel to the device. The tunneled packets will only be routed via this
device.
For more information, refer to man 5 ifcfg-tunnel.
13.6.1.6 Handling Incremental Changes #Edit source
With wicked, there is no need to actually take down an
interface to reconfigure it (unless it is required by the kernel). For
example, to add another IP address or route to a statically configured
network interface, add the IP address to the interface definition, and do
another “ifup” operation. The server will try hard to update
only those settings that have changed. This applies to link-level options
such as the device MTU or the MAC address, and network-level settings, such
as addresses, routes, or even the address configuration mode (for example,
when moving from a static configuration to DHCP).
Things get tricky of course with virtual interfaces combining several real devices such as bridges or bonds. For bonded devices, it is not possible to change certain parameters while the device is up. Doing that will result in an error.
However, what should still work, is the act of adding or removing the child devices of a bond or bridge, or choosing a bond's primary interface.
13.6.1.7 Wicked Extensions: Address Configuration #Edit source
wicked is designed to be extensible with shell scripts.
These extensions can be defined in the config.xml
file.
Currently, several classes of extensions are supported:
link configuration: these are scripts responsible for setting up a device's link layer according to the configuration provided by the client, and for tearing it down again.
address configuration: these are scripts responsible for managing a device's address configuration. Usually address configuration and DHCP are managed by
wickeditself, but can be implemented by means of extensions.firewall extension: these scripts can apply firewall rules.
Typically, extensions have a start and a stop command, an optional “pid file”, and a set of environment variables that get passed to the script.
To illustrate how this is supposed to work, look at a firewall extension
defined in etc/server.xml:
<dbus-service interface="org.opensuse.Network.Firewall"> <action name="firewallUp" command="/etc/wicked/extensions/firewall up"/> <action name="firewallDown" command="/etc/wicked/extensions/firewall down"/> <!-- default environment for all calls to this extension script --> <putenv name="WICKED_OBJECT_PATH" value="$object-path"/> <putenv name="WICKED_INTERFACE_NAME" value="$property:name"/> <putenv name="WICKED_INTERFACE_INDEX" value="$property:index"/> </dbus-service>
The extension is attached to the
<dbus-service>
tag and defines commands to execute for the actions of this interface.
Further, the declaration can define and initialize environment variables
passed to the actions.
13.6.1.8 Wicked Extensions: Configuration Files #Edit source
You can extend the handling of configuration files with scripts as well.
For example, DNS updates from leases are ultimately handled by the
extensions/resolver script, with behavior configured
in server.xml:
<system-updater name="resolver"> <action name="backup" command="/etc/wicked/extensions/resolver backup"/> <action name="restore" command="/etc/wicked/extensions/resolver restore"/> <action name="install" command="/etc/wicked/extensions/resolver install"/> <action name="remove" command="/etc/wicked/extensions/resolver remove"/> </system-updater>
When an update arrives in wickedd, the system
updater routines parse the lease and call the appropriate commands
(backup, install, etc.) in the
resolver script. This in turn configures the DNS settings using
/sbin/netconfig, or by manually writing
/run/netconfig/resolv.conf as a fallback.
13.6.2 Configuration Files #Edit source
This section provides an overview of the network configuration files and explains their purpose and the format used.
13.6.2.1 /etc/wicked/common.xml #Edit source
The /etc/wicked/common.xml file contains common
definitions that should be used by all applications. It is sourced/included
by the other configuration files in this directory. Although you can use
this file to enable debugging across all
wicked components, we recommend to use the file
/etc/wicked/local.xml for this purpose. After applying
maintenance updates you might lose your changes as the
/etc/wicked/common.xml might be overwritten. The
/etc/wicked/common.xml file includes the
/etc/wicked/local.xml in the default installation, thus
you typically do not need to modify the
/etc/wicked/common.xml.
In case you want to disable nanny by setting the
<use-nanny> to false, restart
the wickedd.service and then run the following command to
apply all configurations and policies:
tux >sudowicked ifup all
Note: Configuration Files
The wickedd, wicked, or
nanny programs try to read
/etc/wicked/common.xml if their own configuration
files do not exist.
13.6.2.2 /etc/wicked/server.xml #Edit source
The file /etc/wicked/server.xml is read by the
wickedd server process at start-up. The file stores
extensions to the /etc/wicked/common.xml. On top of
that this file configures handling of a resolver and receiving information
from addrconf supplicants, for example DHCP.
We recommend to add changes required to this file into a separate file
/etc/wicked/server-local.xml, that gets included by
/etc/wicked/server.xml. By using a separate file
you avoid overwriting of your changes during maintenance updates.
13.6.2.3 /etc/wicked/client.xml #Edit source
The /etc/wicked/client.xml is used by the
wicked command. The file specifies the location of a
script used when discovering devices managed by ibft and configures
locations of network interface configurations.
We recommend to add changes required to this file into a separate file
/etc/wicked/client-local.xml, that gets included by
/etc/wicked/server.xml. By using a separate file
you avoid overwriting of your changes during maintenance updates.
13.6.2.4 /etc/wicked/nanny.xml #Edit source
The /etc/wicked/nanny.xml configures types of link
layers. We recommend to add specific configuration into a separate file:
/etc/wicked/nanny-local.xml to avoid losing the changes
during maintenance updates.
13.6.2.5 /etc/sysconfig/network/ifcfg-* #Edit source
These files contain the traditional configurations for network interfaces. In openSUSE prior to Leap, this was the only supported format besides iBFT firmware.
Note: wicked and the ifcfg-* Files
wicked reads these files if you specify the
compat: prefix. According to the openSUSE Leap default
configuration in /etc/wicked/client.xml,
wicked tries these files before the XML configuration
files in /etc/wicked/ifconfig.
The --ifconfig switch is provided mostly for testing only.
If specified, default configuration sources defined in
/etc/wicked/ifconfig are not applied.
The ifcfg-* files include information such as the start
mode and the IP address. Possible parameters are described in the manual
page of ifup. Additionally, most variables from the
dhcp and wireless files can be
used in the ifcfg-* files if a general setting should
be used for only one interface. However, most of the
/etc/sysconfig/network/config variables are global and
cannot be overridden in ifcfg-files. For example,
NETCONFIG_* variables are global.
For configuring macvlan and
macvtab interfaces, see the
ifcfg-macvlan and
ifcfg-macvtap man pages. For example, for a macvlan
interface provide a ifcfg-macvlan0 with settings as
follows:
STARTMODE='auto' MACVLAN_DEVICE='eth0' #MACVLAN_MODE='vepa' #LLADDR=02:03:04:05:06:aa
For ifcfg.template, see
Section 13.6.2.6, “/etc/sysconfig/network/config, /etc/sysconfig/network/dhcp, and /etc/sysconfig/network/wireless”.
13.6.2.6 /etc/sysconfig/network/config, /etc/sysconfig/network/dhcp, and /etc/sysconfig/network/wireless #Edit source
The file config contains general settings for the
behavior of ifup, ifdown and
ifstatus. dhcp contains settings for
DHCP and wireless for wireless LAN cards. The variables
in all three configuration files are commented. Some variables from
/etc/sysconfig/network/config can also be used in
ifcfg-* files, where they are given a higher priority.
The /etc/sysconfig/network/ifcfg.template file lists
variables that can be specified in a per interface scope. However, most of
the /etc/sysconfig/network/config variables are global
and cannot be overridden in ifcfg-files. For example,
NETWORKMANAGER or
NETCONFIG_* variables are global.
Note: Using DHCPv6
In openSUSE prior to Leap, DHCPv6 used to work even on networks where IPv6 Router Advertisements (RAs) were not configured properly. Starting with openSUSE Leap, DHCPv6 will correctly require that at least one of the routers on the network sends out RAs that indicate that this network is managed by DHCPv6.
For networks where the router cannot be configured correctly, the ifcfg option allows the user to override this
behavior by specifying DHCLIENT6_MODE='managed' in the
ifcfg file.
You can also activate this workaround with a boot parameter in the
installation system:
ifcfg=eth0=dhcp6,DHCLIENT6_MODE=managed
13.6.2.7 /etc/sysconfig/network/routes and /etc/sysconfig/network/ifroute-* #Edit source
The static routing of TCP/IP packets is determined by the
/etc/sysconfig/network/routes and
/etc/sysconfig/network/ifroute-* files. All the static
routes required by the various system tasks can be specified in
/etc/sysconfig/network/routes: routes to a host, routes
to a host via a gateway and routes to a network. For each interface that
needs individual routing, define an additional configuration file:
/etc/sysconfig/network/ifroute-*. Replace the wild card
(*) with the name of the interface. The entries in the
routing configuration files look like this:
# Destination Gateway Netmask Interface Options
The route's destination is in the first column. This column may contain the
IP address of a network or host or, in the case of
reachable name servers, the fully qualified network or
host name. The network should be written in CIDR notation (address with the
associated routing prefix-length) such as 10.10.0.0/16 for IPv4 or fc00::/7
for IPv6 routes. The keyword default indicates that the
route is the default gateway in the same address family as the gateway. For
devices without a gateway use explicit 0.0.0.0/0 or ::/0 destinations.
The second column contains the default gateway or a gateway through which a host or network can be accessed.
The third column is deprecated; it used to contain the IPv4 netmask of the
destination. For IPv6 routes, the default route, or when using a
prefix-length (CIDR notation) in the first column, enter a dash
(-) here.
The fourth column contains the name of the interface. If you leave it empty
using a dash (-), it can cause unintended behavior in
/etc/sysconfig/network/routes. For more information,
see the routes man page.
An (optional) fifth column can be used to specify special options. For
details, see the routes man page.
Example 13.5: Common Network Interfaces and Some Static Routes #
# --- IPv4 routes in CIDR prefix notation: # Destination [Gateway] - Interface 127.0.0.0/8 - - lo 204.127.235.0/24 - - eth0 default 204.127.235.41 - eth0 207.68.156.51/32 207.68.145.45 - eth1 192.168.0.0/16 207.68.156.51 - eth1 # --- IPv4 routes in deprecated netmask notation" # Destination [Dummy/Gateway] Netmask Interface # 127.0.0.0 0.0.0.0 255.255.255.0 lo 204.127.235.0 0.0.0.0 255.255.255.0 eth0 default 204.127.235.41 0.0.0.0 eth0 207.68.156.51 207.68.145.45 255.255.255.255 eth1 192.168.0.0 207.68.156.51 255.255.0.0 eth1 # --- IPv6 routes are always using CIDR notation: # Destination [Gateway] - Interface 2001:DB8:100::/64 - - eth0 2001:DB8:100::/32 fe80::216:3eff:fe6d:c042 - eth0
13.6.2.8 /var/run/netconfig/resolv.conf #Edit source
The domain to which the host belongs is specified in
/var/run/netconfig/resolv.conf (keyword
search). Up to six domains with a total of 256
characters can be specified with the search option.
When resolving a name that is not fully qualified, an attempt is made to
generate one by attaching the individual search
entries. Up to three name servers can be specified with the
nameserver option, each on a line of its own.
Comments are preceded by hash mark or semicolon signs (#
or ;). As an example, see
Example 13.6, “/var/run/netconfig/resolv.conf”.
However, /etc/resolv.conf should not be edited by
hand. It is generated by the netconfig script and is a
symbolic link to /run/netconfig/resolv.conf.
To define static DNS configuration without using YaST, edit the
appropriate variables manually in the
/etc/sysconfig/network/config file:
NETCONFIG_DNS_STATIC_SEARCHLISTlist of DNS domain names used for host name lookup
NETCONFIG_DNS_STATIC_SERVERSlist of name server IP addresses to use for host name lookup
NETCONFIG_DNS_FORWARDERthe name of the DNS forwarder that needs to be configured, for example
bindorresolverNETCONFIG_DNS_RESOLVER_OPTIONSarbitrary options that will be written to
/var/run/netconfig/resolv.conf, for example:debug attempts:1 timeout:10
For more information, see the
resolv.confman page.NETCONFIG_DNS_RESOLVER_SORTLISTlist of up to 10 items, for example:
130.155.160.0/255.255.240.0 130.155.0.0
For more information, see the
resolv.confman page.
To disable DNS configuration using netconfig, set
NETCONFIG_DNS_POLICY=''. For more information about
netconfig, see the netconfig(8)
man page (man 8 netconfig).
Example 13.6: /var/run/netconfig/resolv.conf #
# Our domain search example.com # # We use dns.example.com (192.168.1.116) as nameserver nameserver 192.168.1.116
13.6.2.9 /sbin/netconfig #Edit source
netconfig is a modular tool to manage additional network
configuration settings. It merges statically defined settings with settings
provided by autoconfiguration mechanisms as DHCP or PPP according to a
predefined policy. The required changes are applied to the system by calling
the netconfig modules that are responsible for modifying a configuration
file and restarting a service or a similar action.
netconfig recognizes three main actions. The
netconfig modify and netconfig remove
commands are used by daemons such as DHCP or PPP to provide or remove
settings to netconfig. Only the netconfig update command
is available for the user:
modifyThe
netconfig modifycommand modifies the current interface and service specific dynamic settings and updates the network configuration. Netconfig reads settings from standard input or from a file specified with the--lease-file FILENAMEoption and internally stores them until a system reboot (or the next modify or remove action). Already existing settings for the same interface and service combination are overwritten. The interface is specified by the-i INTERFACE_NAMEparameter. The service is specified by the-s SERVICE_NAMEparameter.removeThe
netconfig removecommand removes the dynamic settings provided by a modificatory action for the specified interface and service combination and updates the network configuration. The interface is specified by the-i INTERFACE_NAMEparameter. The service is specified by the-s SERVICE_NAMEparameter.updateThe
netconfig updatecommand updates the network configuration using current settings. This is useful when the policy or the static configuration has changed. Use the-m MODULE_TYPEparameter to update a specified service only (dns,nis, orntp).
The netconfig policy and the static configuration settings are defined
either manually or using YaST in the
/etc/sysconfig/network/config file. The dynamic
configuration settings provided by autoconfiguration tools such as DHCP or
PPP are delivered directly by these tools with the netconfig
modify and netconfig remove actions.
When NetworkManager is enabled, netconfig (in policy mode auto)
uses only NetworkManager settings, ignoring settings from any other interfaces
configured using the traditional ifup method. If NetworkManager does not provide any
setting, static settings are used as a fallback. A mixed usage of NetworkManager and
the wicked method is not supported.
For more information about netconfig, see man 8
netconfig.
13.6.2.10 /etc/hosts #Edit source
In this file, shown in Example 13.7, “/etc/hosts”, IP addresses
are assigned to host names. If no name server is implemented, all hosts to
which an IP connection will be set up must be listed here. For each host,
enter a line consisting of the IP address, the fully qualified host name,
and the host name into the file. The IP address must be at the beginning of
the line and the entries separated by blanks and tabs. Comments are always
preceded by the # sign.
Example 13.7: /etc/hosts #
127.0.0.1 localhost 192.168.2.100 jupiter.example.com jupiter 192.168.2.101 venus.example.com venus
13.6.2.11 /etc/networks #Edit source
Here, network names are converted to network addresses. The format is
similar to that of the hosts file, except the network
names precede the addresses. See Example 13.8, “/etc/networks”.
Example 13.8: /etc/networks #
loopback 127.0.0.0 localnet 192.168.0.0
13.6.2.12 /etc/host.conf #Edit source
Name resolution—the translation of host and network names via the
resolver library—is controlled by this file. This
file is only used for programs linked to libc4 or libc5. For current glibc
programs, refer to the settings in /etc/nsswitch.conf.
Each parameter must always be entered on a separate line. Comments are
preceded by a # sign.
Table 13.2, “Parameters for /etc/host.conf” shows the parameters available. A
sample /etc/host.conf is shown in
Example 13.9, “/etc/host.conf”.
Table 13.2: Parameters for /etc/host.conf #
|
order hosts, bind |
Specifies in which order the services are accessed for the name resolution. Available arguments are (separated by blank spaces or commas): |
|
hosts: searches the
| |
|
bind: accesses a name server | |
|
nis: uses NIS | |
|
multi on/off |
Defines if a host entered in |
|
nospoof on spoofalert on/off |
These parameters influence the name server spoofing but do not exert any influence on the network configuration. |
|
trim domainname |
The specified domain name is separated from the host name after host
name resolution (as long as the host name includes the domain name).
This option is useful only if names from the local domain are in the
|
Example 13.9: /etc/host.conf #
# We have named running order hosts bind # Allow multiple address multi on
13.6.2.13 /etc/nsswitch.conf #Edit source
The introduction of the GNU C Library 2.0 was accompanied by the
introduction of the Name Service Switch (NSS). Refer to
the nsswitch.conf(5) man page and The GNU
C Library Reference Manual for details.
The order for queries is defined in the file
/etc/nsswitch.conf. A sample
nsswitch.conf is shown in
Example 13.10, “/etc/nsswitch.conf”. Comments are preceded by
# signs. In this example, the entry under the
hosts database means that a request is sent to
/etc/hosts (files) via
DNS (see Chapter 19, The Domain Name System).
Example 13.10: /etc/nsswitch.conf #
passwd: compat group: compat hosts: files dns networks: files dns services: db files protocols: db files rpc: files ethers: files netmasks: files netgroup: files nis publickey: files bootparams: files automount: files nis aliases: files nis shadow: compat
The “databases” available over NSS are listed in Table 13.3, “Databases Available via /etc/nsswitch.conf”. The configuration options for NSS databases are listed in Table 13.4, “Configuration Options for NSS “Databases””.
Table 13.3: Databases Available via /etc/nsswitch.conf #
|
|
Mail aliases implemented by |
|
|
Ethernet addresses. |
|
|
List of networks and their subnet masks. Only needed, if you use subnetting. |
|
|
User groups used by |
|
|
Host names and IP addresses, used by |
|
|
Valid host and user lists in the network for controlling access
permissions; see the |
|
|
Network names and addresses, used by |
|
|
Public and secret keys for Secure_RPC used by NFS and NIS+. |
|
|
User passwords, used by |
|
|
Network protocols, used by |
|
|
Remote procedure call names and addresses, used by
|
|
|
Network services, used by |
|
|
Shadow passwords of users, used by |
Table 13.4: Configuration Options for NSS “Databases” #
|
|
directly access files, for example, |
|
|
access via a database |
|
|
NIS, see also Book “Security Guide”, Chapter 3 “Using NIS” |
|
|
can only be used as an extension for |
|
|
can only be used as an extension for |
13.6.2.14 /etc/nscd.conf #Edit source
This file is used to configure nscd (name service cache daemon). See the
nscd(8) and nscd.conf(5)
man pages. By default, the system entries of passwd,
groups and hostsare cached by nscd. This is important for the
performance of directory services, like NIS and LDAP, because otherwise the
network connection needs to be used for every access to names, groups or
hosts.
If the caching for passwd is activated, it usually takes
about fifteen seconds until a newly added local user is recognized. Reduce
this waiting time by restarting nscd with:
tux >sudosystemctl restart nscd
13.6.2.15 /etc/HOSTNAME #Edit source
/etc/HOSTNAME contains the fully qualified host name
(FQHN). The fully qualified host name is the host name with the domain name
attached. This file must contain only one line (in which the host name is
set). It is read while the machine is booting.
13.6.3 Testing the Configuration #Edit source
Before you write your configuration to the configuration files, you can test
it. To set up a test configuration, use the ip command.
To test the connection, use the ping command.
The command ip changes the network configuration directly
without saving it in the configuration file. Unless you enter your
configuration in the correct configuration files, the changed network
configuration is lost on reboot.
Note: ifconfig and route Are Obsolete
The ifconfig and route tools are
obsolete. Use ip instead. ifconfig,
for example, limits interface names to 9 characters.
13.6.3.1 Configuring a Network Interface with ip #Edit source
ip is a tool to show and configure network devices,
routing, policy routing, and tunnels.
ip is a very complex tool. Its common syntax is
ip OPTIONS
OBJECT
COMMAND. You can work with the
following objects:
- link
This object represents a network device.
- address
This object represents the IP address of device.
- neighbor
This object represents an ARP or NDISC cache entry.
- route
This object represents the routing table entry.
- rule
This object represents a rule in the routing policy database.
- maddress
This object represents a multicast address.
- mroute
This object represents a multicast routing cache entry.
- tunnel
This object represents a tunnel over IP.
If no command is given, the default command is used (usually
list).
Change the state of a device with the command:
tux >sudoip link set DEV_NAME
For example, to deactivate device eth0, enter
tux >sudoip link set eth0 down
To activate it again, use
tux >sudoip link set eth0 up
Tip: Disconnecting NIC Device
If you deactivate a device with
tux >sudoip link set DEV_NAME down
it disables the network interface on a software level.
If you want to simulate losing the link as if the ethernet cable is unplugged or the connected switch is turned off, run
tux >sudoip link set DEV_NAME carrier off
For example, while ip link set
DEV_NAME down drops all routes using
DEV_NAME, ip link set DEV carrier
off does not. Be aware that carrier off
requires support from the network device driver.
To connect the device back to the physical network, run
tux >sudoip link set DEV_NAME carrier on
After activating a device, you can configure it. To set the IP address, use
tux >sudoip addr add IP_ADDRESS + dev DEV_NAME
For example, to set the address of the interface eth0 to 192.168.12.154/30
with standard broadcast (option brd), enter
tux >sudoip addr add 192.168.12.154/30 brd + dev eth0
To have a working connection, you must also configure the default gateway. To set a gateway for your system, enter
tux >sudoip route add default via gateway_ip_address
To display all devices, use
tux >sudoip link ls
To display the running interfaces only, use
tux >sudoip link ls up
To print interface statistics for a device, enter
tux >sudoip -s link ls DEV_NAME
To view additional useful information, specifically about virtual network devices, enter
tux >sudoip -d link ls DEV_NAME
Moreover, to view network layer (IPv4, IPv6) addresses of your devices, enter
tux >sudoip addr
In the output, you can find information about MAC addresses of your devices. To show all routes, use
tux >sudoip route show
For more information about using ip, enter
ip help or see the
man 8 ip manual page. The help option
is also available for all ip subcommands, such as:
tux >sudoip addr help
Find the ip manual in
/usr/share/doc/packages/iproute2/ip-cref.pdf.
13.6.3.2 Testing a Connection with ping #Edit source
The ping command is the standard tool for testing
whether a TCP/IP connection works. It uses the ICMP protocol to send a
small data packet, ECHO_REQUEST datagram, to the destination host,
requesting an immediate reply. If this works, ping
displays a message to that effect. This indicates that the network link is
functioning.
ping does more than only test the function of the
connection between two computers: it also provides some basic information
about the quality of the connection. In
Example 13.11, “Output of the Command ping”, you can see an example of the
ping output. The second-to-last line contains
information about the number of transmitted packets, packet loss, and total
time of ping running.
As the destination, you can use a host name or IP address, for example,
ping example.com or
ping 192.168.3.100. The program sends
packets until you press
Ctrl–C.
If you only need to check the functionality of the connection, you can
limit the number of the packets with the -c option. For
example to limit ping to three packets, enter
ping -c 3 example.com.
Example 13.11: Output of the Command ping #
ping -c 3 example.com PING example.com (192.168.3.100) 56(84) bytes of data. 64 bytes from example.com (192.168.3.100): icmp_seq=1 ttl=49 time=188 ms 64 bytes from example.com (192.168.3.100): icmp_seq=2 ttl=49 time=184 ms 64 bytes from example.com (192.168.3.100): icmp_seq=3 ttl=49 time=183 ms --- example.com ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2007ms rtt min/avg/max/mdev = 183.417/185.447/188.259/2.052 ms
The default interval between two packets is one second. To change the
interval, ping provides the option -i. For example, to
increase the ping interval to ten seconds, enter
ping -i 10 example.com.
In a system with multiple network devices, it is sometimes useful to send
the ping through a specific interface address. To do so, use the
-I option with the name of the selected device, for
example, ping -I wlan1
example.com.
For more options and information about using ping, enter
ping -h or see the
ping (8) man page.
Tip: Pinging IPv6 Addresses
For IPv6 addresses use the ping6 command. Note, to ping
link-local addresses, you must specify the interface with
-I. The following command works, if the address is
reachable via eth1:
ping6 -I eth1 fe80::117:21ff:feda:a425
13.6.4 Unit Files and Start-Up Scripts #Edit source
Apart from the configuration files described above, there are also systemd
unit files and various scripts that load the network services while the
machine is booting. These are started when the system is switched to the
multi-user.target target. Some of these unit files
and scripts are described in Some Unit Files and Start-Up Scripts for Network Programs. For
more information about systemd, see
Chapter 10, The systemd Daemon and for more information about the
systemd targets, see the man page of
systemd.special (man
systemd.special).
Some Unit Files and Start-Up Scripts for Network Programs #
network.targetnetwork.targetis the systemd target for networking, but its mean depends on the settings provided by the system administrator.For more information, see http://www.freedesktop.org/wiki/Software/systemd/NetworkTarget/.
multi-user.targetmulti-user.targetis the systemd target for a multiuser system with all required network services.rpcbindStarts the rpcbind utility that converts RPC program numbers to universal addresses. It is needed for RPC services, such as an NFS server.
ypservStarts the NIS server.
ypbindStarts the NIS client.
/etc/init.d/nfsserverStarts the NFS server.
/etc/init.d/postfixControls the postfix process.
13.7 Basic Router Setup #Edit source
A router is a networking device that delivers and receives data (network packets) to or from more than one network back and forth. You often use a router to connect your local network to the remote network (Internet) or to connect local network segments. With openSUSE Leap you can build a router with features such as NAT (Network Address Translation) or advanced firewalling.
The following are basic steps to turn openSUSE Leap into a router.
Enable forwarding, for example in
/etc/sysctl.d/50-router.confnet.ipv4.conf.all.forwarding = 1 net.ipv6.conf.all.forwarding = 1
Then provide a static IPv4 and IPv6 IP setup for the interfaces. Enabling forwarding disables several mechanisms, for example IPv6 does not accept an IPv6 RA (router advertisement) anymore, which also prevents the creation of a default route.
In many situations (for example, when you can reach the same network via more than one interface, or when VPN usually is used and already on “normal multi-home hosts”), you must disable the IPv4 reverse path filter (this feature does not currently exist for IPv6):
net.ipv4.conf.all.rp_filter = 0
You can also filter with firewall settings instead.
To accept an IPv6 RA (from the router on an external, uplink, or ISP interface) and create a default (or also a more specific) IPv6 route again, set:
net.ipv6.conf.${ifname}.accept_ra = 2 net.ipv6.conf.${ifname}.autoconf = 0(Note: “
eth0.42” needs to be written aseth0/42in a dot-separated sysfs path.)
More router behavior and forwarding dependencies are described in https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt.
To provide IPv6 on your internal (DMZ) interfaces, and announce yourself as
an IPv6 router and “autoconf networks” to the clients, install
and configure radvd in
/etc/radvd.conf, for example:
interface eth0
{
IgnoreIfMissing on; # do not fail if interface missed
AdvSendAdvert on; # enable sending RAs
AdvManagedFlag on; # IPv6 addresses managed via DHCPv6
AdvOtherConfigFlag on; # DNS, NTP... only via DHCPv6
AdvDefaultLifetime 3600; # client default route lifetime of 1 hour
prefix 2001:db8:0:1::/64 # (/64 is default and required for autoconf)
{
AdvAutonomous off; # Disable address autoconf (DHCPv6 only)
AdvValidLifetime 3600; # prefix (autoconf addr) is valid 1 h
AdvPreferredLifetime 1800; # prefix (autoconf addr) is prefered 1/2 h
}
}Configure the firewall to masquerade traffic with NAT from the LAN into the WAN and to block inbound traffic on the WAN interface:
tux >sudofirewall-cmd--permanent --zone=external --change-interface=WAN_INTERFACEtux >sudofirewall-cmd--permanent --zone=external --add-masqueradetux >sudofirewall-cmd--permanent --zone=internal --change-interface=LAN_INTERFACEtux >sudofirewall-cmd--reload
13.8 Setting Up Bonding Devices #Edit source
For some systems, there is a desire to implement network connections that comply to more than the standard data security or availability requirements of a typical Ethernet device. In these cases, several Ethernet devices can be aggregated to a single bonding device.
The configuration of the bonding device is done by means of bonding module
options. The behavior is mainly affected by the mode of the bonding device.
By default, this is active-backup which means
that a different slave device will become active if the active slave fails.
The following bonding modes are available:
- (balance-rr)
Packets are transmitted in round-robin fashion from the first to the last available interface. Provides fault tolerance and load balancing.
- (active-backup)
Only one network interface is active. If it fails, a different interface becomes active. This setting is the default for openSUSE Leap. Provides fault tolerance.
- (balance-xor)
Traffic is split between all available interfaces based on the following policy:
[(source MAC address XOR'd with destination MAC address XOR packet type ID) modulo slave count]Requires support from the switch. Provides fault tolerance and load balancing.- (broadcast)
All traffic is broadcast on all interfaces. Requires support from the switch. Provides fault tolerance.
- (802.3ad)
Aggregates interfaces into groups that share the same speed and duplex settings. Requires
ethtoolsupport in the interface drivers, and a switch that supports and is configured for IEEE 802.3ad Dynamic link aggregation. Provides fault tolerance and load balancing.- (balance-tlb)
Adaptive transmit load balancing. Requires
ethtoolsupport in the interface drivers but not switch support. Provides fault tolerance and load balancing.- (balance-alb)
Adaptive load balancing. Requires
ethtoolsupport in the interface drivers but not switch support. Provides fault tolerance and load balancing.
For a more detailed description of the modes, see https://www.kernel.org/doc/Documentation/networking/bonding.txt.
Tip: Bonding and Xen
Using bonding devices is only of interest for machines where you have multiple real network cards available. In most configurations, this means that you should use the bonding configuration only in Dom0. Only if you have multiple network cards assigned to a VM Guest system it may also be useful to set up the bond in a VM Guest.
To configure a bonding device, use the following procedure:
Run › › .
Use and change the to . Proceed with .

Select how to assign the IP address to the bonding device. Three methods are at your disposal:
No IP Address
Dynamic Address (with DHCP or Zeroconf)
Statically assigned IP Address
Use the method that is appropriate for your environment.
In the tab, select the Ethernet devices that should be included into the bond by activating the related check box.
Edit the and choose a bonding mode.
Make sure that the parameter
miimon=100is added to the . Without this parameter, the data integrity is not checked regularly.Click and leave YaST with to create the device.
13.8.1 Hotplugging of Bonding Slaves #Edit source
In specific network environments (such as High Availability), there are cases when you need to replace a bonding slave interface with another one. The reason may be a constantly failing network device. The solution is to set up hotplugging of bonding slaves.
The bond is configured as usual (according to man 5
ifcfg-bonding), for example:
ifcfg-bond0
STARTMODE='auto' # or 'onboot'
BOOTPROTO='static'
IPADDR='192.168.0.1/24'
BONDING_MASTER='yes'
BONDING_SLAVE_0='eth0'
BONDING_SLAVE_1='eth1'
BONDING_MODULE_OPTS='mode=active-backup miimon=100'
The slaves are specified with STARTMODE=hotplug and
BOOTPROTO=none:
ifcfg-eth0
STARTMODE='hotplug'
BOOTPROTO='none'
ifcfg-eth1
STARTMODE='hotplug'
BOOTPROTO='none'
BOOTPROTO=none uses the ethtool
options (when provided), but does not set the link up on ifup
eth0. The reason is that the slave interface is controlled by the
bond master.
STARTMODE=hotplug causes the slave interface to join the
bond automatically when it is available.
The udev rules in
/etc/udev/rules.d/70-persistent-net.rules need to be
changed to match the device by bus ID (udev KERNELS
keyword equal to "SysFS BusID" as visible in hwinfo
--netcard) instead of by MAC address. This allows replacement of
defective hardware (a network card in the same slot but with a different
MAC) and prevents confusion when the bond changes the MAC address of all its
slaves.
For example:
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*",
KERNELS=="0000:00:19.0", ATTR{dev_id}=="0x0", ATTR{type}=="1",
KERNEL=="eth*", NAME="eth0"
At boot time, the systemd network.service does not
wait for the hotplug slaves, but for the bond to become ready, which
requires at least one available slave. When one of the slave interfaces gets
removed (unbind from NIC driver, rmmod of the NIC driver
or true PCI hotplug remove) from the system, the kernel removes it from the
bond automatically. When a new card is added to the system (replacement of
the hardware in the slot), udev renames it using
the bus-based persistent name rule to the name of the slave, and calls
ifup for it. The ifup call
automatically joins it into the bond.
13.9 Setting Up Team Devices for Network Teaming #Edit source
The term “link aggregation” is the general term which describes combining (or aggregating) a network connection to provide a logical layer. Sometimes you find the terms “channel teaming”, “Ethernet bonding”, “port truncating”, etc. which are synonyms and refer to the same concept.
This concept is widely known as “bonding” and was originally integrated into the Linux kernel (see Section 13.8, “Setting Up Bonding Devices” for the original implementation). The term Network Teaming is used to refer to the new implementation of this concept.
The main difference between bonding and Network Teaming is that teaming supplies a set of small kernel modules responsible for providing an interface for teamd instances. Everything else is handled in user space. This is different from the original bonding implementation which contains all of its functionality exclusively in the kernel. For a comparison refer to Table 13.5, “Feature Comparison between Bonding and Team”.
Table 13.5: Feature Comparison between Bonding and Team #
| Feature | Bonding | Team |
|---|---|---|
| broadcast, round-robin TX policy | yes | yes |
| active-backup TX policy | yes | yes |
| LACP (802.3ad) support | yes | yes |
| hash-based TX policy | yes | yes |
| user can set hash function | no | yes |
| TX load-balancing support (TLB) | yes | yes |
| TX load-balancing support for LACP | no | yes |
| Ethtool link monitoring | yes | yes |
| ARP link monitoring | yes | yes |
| NS/NA (IPV6) link monitoring | no | yes |
| RCU locking on TX/RX paths | no | yes |
| port prio and stickiness | no | yes |
| separate per-port link monitoring setup | no | yes |
| multiple link monitoring setup | limited | yes |
| VLAN support | yes | yes |
| multiple device stacking | yes | yes |
| Source: http://libteam.org/files/teamdev.pp.pdf | ||
Both implementations, bonding and Network Teaming, can be used in parallel. Network Teaming is an alternative to the existing bonding implementation. It does not replace bonding.
Network Teaming can be used for different use cases. The two most important use cases are explained later and involve:
Load balancing between different network devices.
Failover from one network device to another in case one of the devices should fail.
Currently, there is no YaST module to support creating a teaming device. You need to configure Network Teaming manually. The general procedure is shown below which can be applied for all your Network Teaming configurations:
Procedure 13.1: General Procedure #
Make sure you have all the necessary packages installed. Install the packages libteam-tools, libteamdctl0, and python-libteam.
Create a configuration file under
/etc/sysconfig/network/. Usually it will beifcfg-team0. If you need more than one Network Teaming device, give them ascending numbers.This configuration file contains several variables which are explained in the man pages (see
man ifcfgandman ifcfg-team). An example configuration can be found in your system in the file/etc/sysconfig/network/ifcfg.template.Remove the configuration files of the interfaces which will be used for the teaming device (usually
ifcfg-eth0andifcfg-eth1).It is recommended to make a backup and remove both files. Wicked will re-create the configuration files with the necessary parameters for teaming.
Optionally, check if everything is included in Wicked's configuration file:
tux >sudowicked show-configStart the Network Teaming device
team0:tux >sudowicked ifup all team0In case you need additional debug information, use the option
--debug allafter theallsubcommand.Check the status of the Network Teaming device. This can be done by the following commands:
Get the state of the teamd instance from Wicked:
tux >sudowicked ifstatus --verbose team0Get the state of the entire instance:
tux >sudoteamdctl team0 stateGet the systemd state of the teamd instance:
tux >sudosystemctl status teamd@team0
Each of them shows a slightly different view depending on your needs.
In case you need to change something in the
ifcfg-team0file afterward, reload its configuration with:tux >sudowicked ifreload team0
Do not use systemctl for starting or
stopping the teaming device! Instead, use the wicked
command as shown above.
To completely remove the team device, use this procedure:
Procedure 13.2: Removing a Team Device #
Stop the Network Teaming device
team0:tux >sudowicked ifdown team0Rename the file
/etc/sysconfig/network/ifcfg-team0to/etc/sysconfig/network/.ifcfg-team0. Inserting a dot in front of the file name makes it “invisible” for wicked. If you really do not need the configuration anymore, you can also remove the file.Reload the configuration:
tux >sudowicked ifreload all
13.9.1 Use Case: Load Balancing with Network Teaming #Edit source
Load balancing is used to improve bandwidth. Use the following configuration
file to create a Network Teaming device with load balancing capabilities. Proceed
with Procedure 13.1, “General Procedure” to set up the device. Check the
output with teamdctl.
Example 13.12: Configuration for Load Balancing with Network Teaming #
STARTMODE=auto 1 BOOTPROTO=static 2 IPADDRESS="192.168.1.1/24" 2 IPADDR6="fd00:deca:fbad:50::1/64" 2 TEAM_RUNNER="loadbalance" 3 TEAM_LB_TX_HASH="ipv4,ipv6,eth,vlan" TEAM_LB_TX_BALANCER_NAME="basic" TEAM_LB_TX_BALANCER_INTERVAL="100" TEAM_PORT_DEVICE_0="eth0" 4 TEAM_PORT_DEVICE_1="eth1" 4 TEAM_LW_NAME="ethtool" 5 TEAM_LW_ETHTOOL_DELAY_UP="10" 6 TEAM_LW_ETHTOOL_DELAY_DOWN="10" 6
Controls the start of the teaming device. The value of
In case you need to control the device yourself (and prevent it from
starting automatically), set | |
Sets a static IP address (here
If the Network Teaming device should use a dynamic IP address, set
| |
Sets | |
Specifies one or more devices which should be aggregated to create the Network Teaming device. | |
Defines a link watcher to monitor the state of subordinate devices. The
default value
If you need a higher confidence in the connection, use the
| |
Defines the delay in milliseconds between the link coming up (or down) and the runner being notified. |
13.9.2 Use Case: Failover with Network Teaming #Edit source
Failover is used to ensure high availability of a critical Network Teaming device by involving a parallel backup network device. The backup network device is running all the time and takes over if and when the main device fails.
Use the following configuration file to create a Network Teaming device with
failover capabilities. Proceed with Procedure 13.1, “General Procedure” to
set up the device. Check the output with teamdctl.
Example 13.13: Configuration for DHCP Network Teaming Device #
STARTMODE=auto 1 BOOTPROTO=static 2 IPADDR="192.168.1.2/24" 2 IPADDR6="fd00:deca:fbad:50::2/64" 2 TEAM_RUNNER=activebackup 3 TEAM_PORT_DEVICE_0="eth0" 4 TEAM_PORT_DEVICE_1="eth1" 4 TEAM_LW_NAME=ethtool 5 TEAM_LW_ETHTOOL_DELAY_UP="10" 6 TEAM_LW_ETHTOOL_DELAY_DOWN="10" 6
Controls the start of the teaming device. The value of
In case you need to control the device yourself (and prevent it from
starting automatically), set | |
Sets a static IP address (here
If the Network Teaming device should use a dynamic IP address, set
| |
Sets | |
Specifies one or more devices which should be aggregated to create the Network Teaming device. | |
Defines a link watcher to monitor the state of subordinate devices. The
default value
If you need a higher confidence in the connection, use the
| |
Defines the delay in milliseconds between the link coming up (or down) and the runner being notified. |
13.9.3 Use Case: VLAN over Team Device #Edit source
VLAN is an abbreviation of Virtual Local Area Network. It allows the running of multiple logical (virtual) Ethernets over one single physical Ethernet. It logically splits the network into different broadcast domains so that packets are only switched between ports that are designated for the same VLAN.
The following use case creates two static VLANs on top of a team device:
vlan0, bound to the IP address192.168.10.1vlan1, bound to the IP address192.168.20.1
Proceed as follows:
Enable the VLAN tags on your switch. To use load balancing for your team device, your switch needs to be capable of Link Aggregation Control Protocol (LACP) (802.3ad). Consult your hardware manual about the details.
Decide if you want to use load balancing or failover for your team device. Set up your team device as described in Section 13.9.1, “Use Case: Load Balancing with Network Teaming” or Section 13.9.2, “Use Case: Failover with Network Teaming”.
In
/etc/sysconfig/networkcreate a fileifcfg-vlan0with the following content:STARTMODE="auto" BOOTPROTO="static" 1 IPADDR='192.168.10.1/24' 2 ETHERDEVICE="team0" 3 VLAN_ID="0" 4 VLAN='yes'
Defines a fixed IP address, specified in
IPADDR.Defines the IP address, here with its netmask.
Contains the real interface to use for the VLAN interface, here our team device (
team0).Specifies a unique ID for the VLAN. Preferably, the file name and the
VLAN_IDcorresponds to the nameifcfg-vlanVLAN_ID. In our caseVLAN_IDis0which leads to the file nameifcfg-vlan0.Copy the file
/etc/sysconfig/network/ifcfg-vlan0to/etc/sysconfig/network/ifcfg-vlan1and change the following values:IPADDRfrom192.168.10.1/24to192.168.20.1/24.VLAN_IDfrom0to1.
Start the two VLANs:
root #wickedifup vlan0 vlan1Check the output of
ifconfig:root #ifconfig-a [...] vlan0 Link encap:Ethernet HWaddr 08:00:27:DC:43:98 inet addr:192.168.10.1 Bcast:192.168.10.255 Mask:255.255.255.0 inet6 addr: fe80::a00:27ff:fedc:4398/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:12 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:0 (0.0 b) TX bytes:816 (816.0 b) vlan1 Link encap:Ethernet HWaddr 08:00:27:DC:43:98 inet addr:192.168.20.1 Bcast:192.168.20.255 Mask:255.255.255.0 inet6 addr: fe80::a00:27ff:fedc:4398/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:0 errors:0 dropped:0 overruns:0 frame:0 TX packets:12 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:0 (0.0 b) TX bytes:816 (816.0 b)
13.10 Software-Defined Networking with Open vSwitch #Edit source
Software-defined networking (SDN) means separating the system that controls where traffic is sent (the control plane) from the underlying system that forwards traffic to the selected destination (the data plane, also called the forwarding plane). This means that the functions previously fulfilled by a single, usually inflexible switch can now be separated between a switch (data plane) and its controller (control plane). In this model, the controller is programmable and can be very flexible and adapt quickly to changing network conditions.
Open vSwitch is software that implements a distributed virtual multilayer switch that is compatible with the OpenFlow protocol. OpenFlow allows a controller application to modify the configuration of a switch. OpenFlow is layered onto the TCP protocol and is implemented in a range of hardware and software. A single controller can thus drive multiple, very different switches.
13.10.1 Advantages of Open vSwitch #Edit source
Software-defined networking with Open vSwitch brings several advantages with it, especially when you used together with virtual machines:
Networking states can be identified easily.
Networks and their live state can be moved from one host to another.
Network dynamics are traceable and external software can be enabled to respond to them.
You can apply and manipulate tags in network packets to identify which machine they are coming from or going to and maintain other networking context. Tagging rules can be configured and migrated.
Open vSwitch implements the GRE protocol (Generic Routing Encapsulation). This allows you, for example, to connect private VM networks to each other.
Open vSwitch can be used on its own, but is designed to integrate with networking hardware and can control hardware switches.
13.10.2 Installing Open vSwitch #Edit source
Install Open vSwitch and supplementary packages:
root #zypperinstall openvswitch openvswitch-switchIf you plan to use Open vSwitch together with the KVM hypervisor, additionally install tunctl . If you plan to use Open vSwitch together with the Xen hypervisor, additionally install openvswitch-kmp-xen .
Enable the Open vSwitch service:
root #systemctlenable openvswitchEither restart the computer or use
systemctlto start the Open vSwitch service immediately:root #systemctlstart openvswitchTo check whether Open vSwitch was activated correctly, use:
root #systemctlstatus openvswitch
13.10.3 Overview of Open vSwitch Daemons and Utilities #Edit source
Open vSwitch consists of several components. Among them are a kernel module and various user space components. The kernel module is used for accelerating the data path, but is not necessary for a minimal Open vSwitch installation.
13.10.3.1 Daemons #Edit source
The central executables of Open vSwitch are its two daemons. When you start the
openvswitch service, you are indirectly starting
them.
The main Open vSwitch daemon (ovs-vswitchd) provides the
implementation of a switch. The Open vSwitch database daemon
(ovsdb-server) serves the database that stores the
configuration and state of Open vSwitch.
13.10.3.2 Utilities #Edit source
Open vSwitch also comes with several utilities that help you work with it. The following list is not exhaustive, but instead describes important commands only.
ovsdb-toolCreate, upgrade, compact, and query Open vSwitch databases. Do transactions on Open vSwitch databases.
ovs-appctlConfigure a running
ovs-vswitchdorovsdb-serverdaemon.ovs-dpctl,ovs-dpctl-topCreate, modify, visualize, and delete data paths. Using this tool can interfere with
ovs-vswitchdalso performing data path management. Therefore, it is often used for diagnostics only.ovs-dpctl-topcreates atop-like visualization for data paths.ovs-ofctlManage any switches adhering to the OpenFlow protocol.
ovs-ofctlis not limited to interacting with Open vSwitch.ovs-vsctlProvides a high-level interface to the configuration database. It can be used to query and modify the database. In effect, it shows the status of
ovs-vswitchdand can be used to configure it.
13.10.4 Creating a Bridge with Open vSwitch #Edit source
The following example configuration uses the Wicked network service that is used by default on openSUSE Leap. To learn more about Wicked, see Section 13.6, “Configuring a Network Connection Manually”.
When you have installed and started Open vSwitch, proceed as follows:
To configure a bridge for use by your virtual machine, create a file with content like this:
STARTMODE='auto'1 BOOTPROTO='dhcp'2 OVS_BRIDGE='yes'3 OVS_BRIDGE_PORT_DEVICE_1='eth0'4
Set up the bridge automatically when the network service is started.
The protocol to use for configuring the IP address.
Mark the configuration as an Open vSwitch bridge.
Choose which device/devices should be added to the bridge. To add more devices, append additional lines for each of them to the file:
OVS_BRIDGE_PORT_DEVICE_SUFFIX='DEVICE'
The SUFFIX can be any alphanumeric string. However, to avoid overwriting a previous definition, make sure the SUFFIX of each device is unique.
Save the file in the directory
/etc/sysconfig/networkunder the nameifcfg-br0. Instead of br0, you can use any name you want. However, the file name needs to begin withifcfg-.To learn about further options, refer to the man pages of
ifcfg(man 5 ifcfg) andifcfg-ovs-bridge(man 5 ifcfg-ovs-bridge).Now start the bridge:
root #wickedifup br0When Wicked is done, it should output the name of the bridge and next to it the state
up.
13.10.5 Using Open vSwitch Directly with KVM #Edit source
After having created the bridge as described in Section 13.10.4, “Creating a Bridge with Open vSwitch”, you can use Open vSwitch to manage the network access of virtual machines created with KVM/QEMU.
To be able to best use the capabilities of Wicked, make some further changes to the bridge configured before. Open the previously created
/etc/sysconfig/network/ifcfg-br0and append a line for another port device:OVS_BRIDGE_PORT_DEVICE_2='tap0'
Additionally, set
BOOTPROTOtonone. The file should now look like this:STARTMODE='auto' BOOTPROTO='none' OVS_BRIDGE='yes' OVS_BRIDGE_PORT_DEVICE_1='eth0' OVS_BRIDGE_PORT_DEVICE_2='tap0'
The new port device tap0 will be configured in the next step.
Now add a configuration file for the tap0 device:
STARTMODE='auto' BOOTPROTO='none' TUNNEL='tap'
Save the file in the directory
/etc/sysconfig/networkunder the nameifcfg-tap0.
Tip: Allowing Other Users to Access the Tap Device
To be able to use this tap device from a virtual machine started as a user who is not
root, append:TUNNEL_SET_OWNER=USER_NAME
To allow access for an entire group, append:
TUNNEL_SET_GROUP=GROUP_NAME
Finally, open the configuration for the device defined as the first
OVS_BRIDGE_PORT_DEVICE. If you did not change the name, that should beeth0. Therefore, open/etc/sysconfig/network/ifcfg-eth0and make sure that the following options are set:STARTMODE='auto' BOOTPROTO='none'
If the file does not exist yet, create it.
Restart the bridge interface using Wicked:
root #wickedifreload br0This will also trigger a reload of the newly defined bridge port devices.
To start a virtual machine, use, for example:
root #qemu-kvm\ -drive file=/PATH/TO/DISK-IMAGE1 \ -m 512 -net nic,vlan=0,macaddr=00:11:22:EE:EE:EE \ -net tap,ifname=tap0,script=no,downscript=no2For further information on the usage of KVM/QEMU, see Book “Virtualization Guide”.
13.10.6 Using Open vSwitch with libvirt #Edit source
After having created the bridge as described before in
Section 13.10.4, “Creating a Bridge with Open vSwitch”, you can add the bridge to an existing
virtual machine managed with libvirt. Since libvirt has some support for
Open vSwitch bridges already, you can use the bridge created in
Section 13.10.4, “Creating a Bridge with Open vSwitch” without further changes to the networking
configuration.
Open the domain XML file for the intended virtual machine:
root #virshedit VM_NAMEReplace VM_NAME with the name of the desired virtual machine. This will open your default text editor.
Find the networking section of the document by looking for a section starting with
<interface type="...">and ending in</interface>.Replace the existing section with a networking section that looks somewhat like this:
<interface type='bridge'> <source bridge='br0'/> <virtualport type='openvswitch'/> </interface>

Important: Compatibility of
virsh iface-*and Virtual Machine Manager with Open vSwitchAt the moment, the Open vSwitch compatibility of
libvirtis not exposed through thevirsh iface-*tools and Virtual Machine Manager. If you use any of these tools, your configuration can break.You can now start or restart the virtual machine as usual.
For further information on the usage of libvirt, see
Book “Virtualization Guide”.
13.10.7 For More Information #Edit source
- http://openvswitch.org/support/
The documentation section of the Open vSwitch project Web site
- https://www.opennetworking.org/images/stories/downloads/sdn-resources/white-papers/wp-sdn-newnorm.pdf
Whitepaper by the Open Networking Foundation about software-defined networking and the OpenFlow protocol