17 Kexec and Kdump
Kexec is a tool to boot to another kernel from the currently running one. You can perform faster system reboots without any hardware initialization. You can also prepare the system to boot to another kernel if the system crashes.
17.1 Introduction #
With Kexec, you can replace the running kernel with another one without a hard reboot. The tool is useful for several reasons:
Faster system rebooting
If you need to reboot the system frequently, Kexec can save you significant time.
Avoiding unreliable firmware and hardware
Computer hardware is complex and serious problems may occur during the system start-up. You cannot always replace unreliable hardware immediately. Kexec boots the kernel to a controlled environment with the hardware already initialized. The risk of unsuccessful system start is then minimized.
Saving the dump of a crashed kernel
Kexec preserves the contents of the physical memory. After the production kernel fails, the capture kernel (an additional kernel running in a reserved memory range) saves the state of the failed kernel. The saved image can help you with the subsequent analysis.
Booting without GRUB 2 configuration
When the system boots a kernel with Kexec, it skips the boot loader stage. The normal booting procedure can fail because of an error in the boot loader configuration. With Kexec, you do not depend on a working boot loader configuration.
17.2 Required Packages #
To use Kexec on openSUSE® Leap to speed up reboots or avoid potential
hardware problems, make sure that the package
kexec-tools is installed.
It contains a script called
kexec-bootloader, which reads the boot loader
configuration and runs Kexec using the same kernel options as the
normal boot loader.
To set up an environment that helps you obtain debug information
in case of a kernel crash, make sure that the package
makedumpfile is installed.
The preferred method of using Kdump in openSUSE Leap is through
the YaST Kdump module.
To use the YaST module, make sure that the package
yast2-kdump is installed.
17.3 Kexec Internals #
The most important component of Kexec is the
/sbin/kexec command. You can load a kernel with
Kexec in two different ways:
Load the kernel to the address space of a production kernel for a regular reboot:
root #kexec-lKERNEL_IMAGEYou can later boot to this kernel with
kexec-e.Load the kernel to a reserved area of memory:
root #kexec-pKERNEL_IMAGEThis kernel will be booted automatically when the system crashes.
If you want to boot another kernel and preserve the data of the production kernel when the system crashes, you need to reserve a dedicated area of the system memory. The production kernel never loads to this area because it must be always available. It is used for the capture kernel so that the memory pages of the production kernel can be preserved.
To reserve the area, append the option crashkernel
to the boot command line of the production kernel.
To determine the necessary values for crashkernel, follow
the instructions in Section 17.4, “Calculating crashkernel Allocation Size”.
Note that this is not a parameter of the capture kernel. The capture kernel does not use Kexec.
The capture kernel is loaded to the reserved area and waits for the kernel to crash. Then, Kdump tries to invoke the capture kernel because the production kernel is no longer reliable at this stage. This means that even Kdump can fail.
To load the capture kernel, you need to include the kernel boot
parameters. Usually, the initial RAM file system is used for booting. You
can specify it with
--initrd=FILENAME.
With
--append=CMDLINE,
you append options to the command line of the kernel to boot.
It is helpful to include the command line of
the production kernel if these options are necessary for the kernel to
boot. You can simply copy the command line with
--append="$(cat /proc/cmdline)"
or add more options with
--append="$(cat /proc/cmdline) more_options".
You can always unload the previously loaded kernel. To unload a kernel
that was loaded with the -l option, use the
kexec -u command. To unload a crash
kernel loaded with the -p option, use
kexec -p -u command.
17.4 Calculating crashkernel Allocation Size #
To use Kexec with a capture kernel and to use Kdump in any way, RAM needs to be allocated for the capture kernel. The allocation size depends on the expected hardware configuration of the computer, therefore you need to specify it.
The allocation size also depends on the hardware architecture of your computer. Make sure to follow the procedure intended for your system architecture.
Procedure 17.1: Allocation Size on AMD64/Intel 64 #
To find out the base value for the computer, run the following in a terminal:
root #kdumptoolcalibrateThis command returns a list of values. All values are given in megabytes.
Write down the values of
LowandHigh.
Note: Significance of
LowandHighValuesOn AMD64/Intel 64 computers, the
Highvalue stands for the memory reservation for all available memory. TheLowvalue stands for the memory reservation in the DMA32 zone, that is, all the memory up to the 4 GB mark.If the computer has less than 4 GB of RAM, the
Highmemory reservation is allocated and theLowmemory reservation is ignored. If the computer has more than 4 GB of RAM, theLowmemory reservation is allocated additionally.Adapt the
Highvalue from the previous step for the number of LUN kernel paths (paths to storage devices) attached to the computer. A sensible value in megabytes can be calculated using this formula:SIZE_HIGH = RECOMMENDATION + (LUNs / 2)
The following parameters are used in this formula:
SIZE_HIGH. The resulting value for
High.RECOMMENDATION. The value recommended by
kdumptool calibrateforHigh.LUNs. The maximum number of LUN kernel paths that you expect to ever create on the computer. Exclude multipath devices from this number, as these are ignored.

Important: Adjust for Large Amounts of RAM
For machines that have multiple terabytes (!) of RAM, such as many servers running SAP HANA, you may have to additionally adjust the amount of both Kdump High and Low Memory.
Experience suggests that in such cases, you might be successful using the following formulas:
SIZE_HIGH = (RECOMMENDATION * RAM_IN_TB) + (LUNs / 2)
SIZE_LOW = (RECOMMENDATION * RAM_IN_TB) + CUSTOM_DRIVER-RESERVATION_ADJUSTMENT
If the drivers for your device make many reservations in the DMA32 zone, the
Lowvalue also needs to be adjusted. However, there is no simple formula to calculate these. Finding the right size can therefore be a process of trial and error.For the beginning, use the
Lowvalue recommended bykdumptool calibrate.The values now need to be set in the correct location.
- If you are changing the kernel command line directly
Append the following kernel option to your boot loader configuration:
crashkernel=SIZE_HIGH,high crashkernel=SIZE_LOW,low
Replace the placeholders SIZE_HIGH and SIZE_LOW with the appropriate value from the previous steps and append the letter
M(for megabytes).As an example, the following is valid:
crashkernel=36M,high crashkernel=72M,low
- If you are using the YaST GUI:
Set to the determined
Lowvalue.Set to the determined
Highvalue.- If you are using the YaST command line interface:
Use the following command:
root #yast kdump startup enable alloc_mem=LOW,HIGHReplace LOW with the determined
Lowvalue. Replace HIGH with the determinedHIGHvalue.
Procedure 17.2: Allocation Size on POWER and z Systems #
To find out the basis value for the computer, run the following in a terminal:
root #kdumptoolcalibrateThis command returns a list of values. All values are given in megabytes.
Write down the value of
Low.Adapt the
Lowvalue from the previous step for the number of LUN kernel paths (paths to storage devices) attached to the computer. A sensible value in megabytes can be calculated using this formula:SIZE_LOW = RECOMMENDATION + (LUNs / 2)
The following parameters are used in this formula:
SIZE_LOW. The resulting value for
Low.RECOMMENDATION. The value recommended by
kdumptool calibrateforLow.LUNs. The maximum number of LUN kernel paths that you expect to ever create on the computer. Exclude multipath devices from this number, as these are ignored.
The values now need to be set in the correct location.
- If you are working on the command line
Append the following kernel option to your boot loader configuration:
crashkernel=SIZE_LOW
Replace the placeholderSIZE_LOW with the appropriate value from the previous step and append the letter
M(for megabytes).As an example, the following is valid:
crashkernel=108M
- If you are working in YaST
Set to the determined
Lowvalue.
Tip: Excluding Unused and Inactive CCW Devices on IBM z Systems
Depending on the number of available devices the calculated amount of
memory specified by the crashkernel kernel parameter may
not be sufficient. Instead of increasing the value, you may alternatively
limit the amount of devices visible to the kernel. This will lower the
required amount of memory for the "crashkernel" setting.
To ignore devices you can run the
cio_ignoretool to generate an appropriate stanza to ignore all devices, except the ones currently active or in use.tux >sudo cio_ignore -u -k cio_ignore=all,!da5d,!f500-f502When you run
cio_ignore -u -k, the blacklist will become active and replace any existing blacklist immediately. Unused devices are not being purged, so they still appear in the channel subsystem. But adding new channel devices (via CP ATTACH under z/VM or dynamic I/O configuration change in LPAR) will treat them as blacklisted. To prevent this, preserve the original setting by runningsudo cio_ignore -lfirst and reverting to that state after runningcio_ignore -u -k. As an alternative, add the generated stanza to the regular kernel boot parameters.Now add the
cio_ignorekernel parameter with the stanza from above toKDUMP_CMDLINE_APPENDin/etc/sysconfig/kdump, for example:KDUMP_COMMANDLINE_APPEND="cio_ignore=all,!da5d,!f500-f502"
Activate the setting by restarting
kdump:systemctl restart kdump.service
17.5 Basic Kexec Usage #
To use Kexec, ensure the respective service is enabled and running:
Make sure the Kexec service is loaded at system start:
tux >sudosystemctl enable kexec-load.serviceMake sure the Kexec service is running:
tux >sudosystemctl start kexec-load.service
To verify if your Kexec environment works properly, try rebooting into a new Kernel with Kexec. Make sure no users are currently logged in and no important services are running on the system. If this is the case, run the following command:
systemctl kexec
The new kernel previously loaded to the address space of the older kernel rewrites it and takes control immediately. It displays the usual start-up messages. When the new kernel boots, it skips all hardware and firmware checks. Make sure no warning messages appear.
Tip: Using Kexec with the reboot command
To make reboot use kexec; rather than performing a
regular reboot, run the following command:
ln -s /usr/lib/systemd/system/kexec.target /etc/systemd/system/reboot.target
You can revert this at any time by deleting
etc/systemd/system/reboot.target.
17.6 How to Configure Kexec for Routine Reboots #
Kexec is often used for frequent reboots. For example, if it takes a long time to run through the hardware detection routines or if the start-up is not reliable.
Note that firmware and the boot loader are not used when the system reboots with Kexec. Any changes you make to the boot loader configuration will be ignored until the computer performs a hard reboot.
17.7 Basic Kdump Configuration #
You can use Kdump to save kernel dumps. If the kernel crashes, it is useful to copy the memory image of the crashed environment to the file system. You can then debug the dump file to find the cause of the kernel crash. This is called “core dump”.
Kdump works similarly to Kexec (see Chapter 17, Kexec and Kdump). The capture kernel is executed after the running production kernel crashes. The difference is that Kexec replaces the production kernel with the capture kernel. With Kdump, you still have access to the memory space of the crashed production kernel. You can save the memory snapshot of the crashed kernel in the environment of the Kdump kernel.
Tip: Dumps over Network
In environments with limited local storage, you need to set up kernel
dumps over the network. Kdump supports configuring the specified
network interface and bringing it up via
initrd. Both LAN and VLAN interfaces are
supported. Specify the network interface and the mode (DHCP or static)
either with YaST, or using the KDUMP_NETCONFIG
option in the /etc/sysconfig/kdump file.
Important: Target File System for Kdump Must Be Mounted During Configuration
When configuring Kdump, you can specify a location to which the
dumped images will be saved (default: /var/crash).
This location must be mounted when configuring Kdump, otherwise the
configuration will fail.
17.7.1 Manual Kdump Configuration #
Kdump reads its configuration from the
/etc/sysconfig/kdump file. To make sure that
Kdump works on your system, its default configuration is
sufficient. To use Kdump with the default settings, follow these
steps:
Determine the amount of memory needed for Kdump by following the instructions in Section 17.4, “Calculating
crashkernelAllocation Size”. Make sure to set the kernel parametercrashkernel.Reboot the computer.
Enable the Kdump service:
root #systemctlenable kdumpYou can edit the options in
/etc/sysconfig/kdump. Reading the comments will help you understand the meaning of individual options.Execute the init script once with
sudo systemctl start kdump, or reboot the system.
After configuring Kdump with the default values, check if it works as expected. Make sure that no users are currently logged in and no important services are running on your system. Then follow these steps:
Switch to the rescue target with
systemctl isolate rescue.targetRestart the Kdump service:
root #systemctlstart kdumpUnmount all the disk file systems except the root file system with:
root #umount-aRemount the root file system in read-only mode:
root #mount-o remount,ro /Invoke a “kernel panic” with the
procfsinterface to Magic SysRq keys:root #echoc > /proc/sysrq-trigger
Important: Size of Kernel Dumps
The KDUMP_KEEP_OLD_DUMPS option controls the number
of preserved kernel dumps (default is 5). Without compression, the size
of the dump can take up to the size of the physical RAM memory. Make
sure you have sufficient space on the /var
partition.
The capture kernel boots and the crashed kernel memory snapshot is saved
to the file system. The save path is given by the
KDUMP_SAVEDIR option and it defaults to
/var/crash. If
KDUMP_IMMEDIATE_REBOOT is set to
yes , the system automatically reboots the production
kernel. Log in and check that the dump has been created under
/var/crash.
17.7.1.1 Static IP Configuration for Kdump #
In case Kdump is configured to use a static IP configuration from a
network device, you have to add the network configuration to the
KDUMP_COMMANDLINE_APPEND variable in
/etc/sysconfig/kdump.
Example 17.1: Kdump: Example Configuration Using a Static IP Setup #
The following setup has been configured:
eth0 has been configured with the static IP address
192.168.1.1/24eth1 has been configured with the static IP address
10.50.50.100/20The Kdump configuration in
/etc/sysconfig/kdumplooks like:KDUMP_CPUS=1 KDUMP_IMMEDIATE_REBOOT=yes KDUMP_SAVEDIR=ftp://anonymous@10.50.50.140/crashdump/ KDUMP_KEEP_OLD_DUMPS=5 KDUMP_FREE_DISK_SIZE=64 KDUMP_VERBOSE=3 KDUMP_DUMPLEVEL=31 KDUMP_DUMPFORMAT=lzo KDUMP_CONTINUE_ON_ERROR=yes KDUMP_NETCONFIG=eth1:static KDUMP_NET_TIMEOUT=30
Using this configuration, Kdump fails to reach the network when trying
to write the dump to the FTP server. To solve this issue, add the network
configuration to KDUMP_COMMANDLINE_APPEND in
/etc/sysconfig/kdump. The general pattern for this
looks like the following:
KDUMP_COMMANDLINE_APPEND='ip=CLIENT IP:SERVER IP:GATEWAY IP:NETMASK:CLIENT HOSTNAME:DEVICE:PROTOCOL'
For the example configuration this would result in:
KDUMP_COMMANDLINE_APPEND='ip=10.50.50.100:10.50.50.140:10.60.48.1:255.255.240.0:dump-client:eth1:none'
17.7.2 YaST Configuration #
To configure Kdump with YaST, you need to install the
yast2-kdump package. Then either start the
module in the
category of , or enter yast2 kdump in the
command line as root.
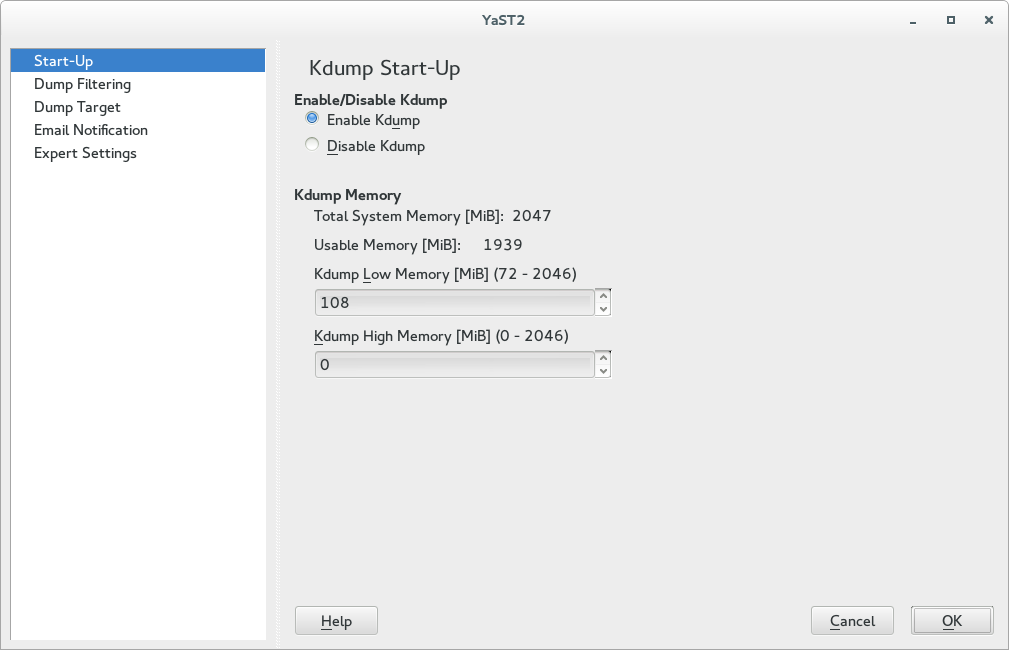
Figure 17.1: YaST Kdump Module: Start-Up Page #
In the window, select .
The values for are automatically generated
the first time you open the window.
However, that does not mean that they are always sufficient.
To set the right values, follow the instructions in
Section 17.4, “Calculating crashkernel Allocation Size”.
Important: After Hardware Changes, Set Values Again
If you have set up Kdump on a computer and later decide to change the amount of RAM or hard disks available to it, YaST will continue to display and use outdated memory values.
To work around this, determine the necessary memory again, as described in
Section 17.4, “Calculating crashkernel Allocation Size”.
Then set it manually in YaST.
Click in the left pane, and check what pages to include in the dump. You do not need to include the following memory content to be able to debug kernel problems:
Pages filled with zero
Cache pages
User data pages
Free pages
In the window, select the type of the dump target and the URL where you want to save the dump. If you selected a network protocol, such as FTP or SSH, you need to enter relevant access information as well.
Tip: Sharing the Dump Directory with Other Applications
It is possible to specify a path for saving Kdump dumps where other applications also save their dumps. When cleaning its old dump files, Kdump will safely ignore other applications' dump files.
Fill the window information if you want Kdump to inform you about its events via e-mail and confirm your changes with after fine tuning Kdump in the window. Kdump is now configured.
17.8 Analyzing the Crash Dump #
After you obtain the dump, it is time to analyze it. There are several options.
The original tool to analyze the dumps is GDB. You can even use it in the latest environments, although it has several disadvantages and limitations:
GDB was not specifically designed to debug kernel dumps.
GDB does not support ELF64 binaries on 32-bit platforms.
GDB does not understand other formats than ELF dumps (it cannot debug compressed dumps).
That is why the crash utility was implemented. It
analyzes crash dumps and debugs the running system as well. It provides
functionality specific to debugging the Linux kernel and is much more
suitable for advanced debugging.
If you want to debug the Linux kernel, you need to install its debugging information package in addition. Check if the package is installed on your system with:
tux >zypperse kernel |grepdebug
Important: Repository for Packages with Debugging Information
If you subscribed your system for online updates, you can find
“debuginfo” packages in the
*-Debuginfo-Updates online installation repository
relevant for openSUSE Leap 42.3. Use YaST to
enable the repository.
To open the captured dump in crash on the machine that
produced the dump, use a command like this:
crash /boot/vmlinux-2.6.32.8-0.1-default.gz \
/var/crash/2010-04-23-11\:17/vmcore
The first parameter represents the kernel image. The second parameter is
the dump file captured by Kdump. You can find this file under
/var/crash by default.
Tip: Getting Basic Information from a Kernel Crash Dump
openSUSE Leap ships with the utility kdumpid
(included in a package with the same name) for identifying unknown
kernel dumps. It can be used to extract basic information such as
architecture and kernel release. It supports lkcd, diskdump, Kdump
files and ELF dumps. When called with the -v
switch it tries to extract additional information such as machine type,
kernel banner string and kernel configuration flavor.
17.8.1 Kernel Binary Formats #
The Linux kernel comes in Executable and Linkable Format (ELF). This
file is usually called vmlinux and is directly
generated in the compilation process. Not all boot loaders support
ELF binaries, especially on the AMD64/Intel 64 architecture.
The following solutions exist on different architectures supported by
openSUSE® Leap.
17.8.1.1 AMD64/Intel 64 #
Kernel packages for AMD64/Intel 64 from SUSE contain two kernel
files: vmlinuz and vmlinux.gz.
vmlinuz. This is the file executed by the boot loader.The Linux kernel consists of two parts: the kernel itself (
vmlinux) and the setup code run by the boot loader. These two parts are linked together to createvmlinuz(note the distinction:zcompared tox).In the kernel source tree, the file is called
bzImage.vmlinux.gz. This is a compressed ELF image that can be used bycrashand GDB. The ELF image is never used by the boot loader itself on AMD64/Intel 64. Therefore, only a compressed version is shipped.
17.8.1.2 POWER #
The yaboot boot loader on POWER also supports
loading ELF images, but not compressed ones. In the POWER kernel package,
there is an ELF Linux kernel file vmlinux.
Considering crash, this is the easiest
architecture.
If you decide to analyze the dump on another machine, you must check both the architecture of the computer and the files necessary for debugging.
You can analyze the dump on another computer only if it runs a Linux
system of the same architecture. To check the compatibility, use the
command uname -i on both computers
and compare the outputs.
If you are going to analyze the dump on another computer, you also need
the appropriate files from the kernel and
kernel debug packages.
Put the kernel dump, the kernel image from
/boot, and its associated debugging info file from/usr/lib/debug/bootinto a single empty directory.Additionally, copy the kernel modules from
/lib/modules/$(uname -r)/kernel/and the associated debug info files from/usr/lib/debug/lib/modules/$(uname -r)/kernel/into a subdirectory namedmodules.In the directory with the dump, the kernel image, its debug info file, and the
modulessubdirectory, start thecrashutility:tux >crashVMLINUX-VERSION vmcore
Regardless of the computer on which you analyze the dump, the crash utility will produce output similar to this:
tux >crash/boot/vmlinux-2.6.32.8-0.1-default.gz \ /var/crash/2010-04-23-11\:17/vmcore crash 4.0-7.6 Copyright (C) 2002, 2003, 2004, 2005, 2006, 2007, 2008 Red Hat, Inc. Copyright (C) 2004, 2005, 2006 IBM Corporation Copyright (C) 1999-2006 Hewlett-Packard Co Copyright (C) 2005, 2006 Fujitsu Limited Copyright (C) 2006, 2007 VA Linux Systems Japan K.K. Copyright (C) 2005 NEC Corporation Copyright (C) 1999, 2002, 2007 Silicon Graphics, Inc. Copyright (C) 1999, 2000, 2001, 2002 Mission Critical Linux, Inc. This program is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Enter "help copying" to see the conditions. This program has absolutely no warranty. Enter "help warranty" for details. GNU gdb 6.1 Copyright 2004 Free Software Foundation, Inc. GDB is free software, covered by the GNU General Public License, and you are welcome to change it and/or distribute copies of it under certain conditions. Type "show copying" to see the conditions. There is absolutely no warranty for GDB. Type "show warranty" for details. This GDB was configured as "x86_64-unknown-linux-gnu"... KERNEL: /boot/vmlinux-2.6.32.8-0.1-default.gz DEBUGINFO: /usr/lib/debug/boot/vmlinux-2.6.32.8-0.1-default.debug DUMPFILE: /var/crash/2009-04-23-11:17/vmcore CPUS: 2 DATE: Thu Apr 23 13:17:01 2010 UPTIME: 00:10:41 LOAD AVERAGE: 0.01, 0.09, 0.09 TASKS: 42 NODENAME: eros RELEASE: 2.6.32.8-0.1-default VERSION: #1 SMP 2010-03-31 14:50:44 +0200 MACHINE: x86_64 (2999 Mhz) MEMORY: 1 GB PANIC: "SysRq : Trigger a crashdump" PID: 9446 COMMAND: "bash" TASK: ffff88003a57c3c0 [THREAD_INFO: ffff880037168000] CPU: 1 STATE: TASK_RUNNING (SYSRQ)crash>
The command output prints first useful data: There were 42 tasks
running at the moment of the kernel crash. The cause of the crash was a
SysRq trigger invoked by the task with PID 9446. It was a Bash process
because the echo that has been used is an internal
command of the Bash shell.
The crash utility builds upon GDB and provides
many additional commands. If you enter bt
without any parameters, the backtrace of the task running at the moment
of the crash is printed:
crash>btPID: 9446 TASK: ffff88003a57c3c0 CPU: 1 COMMAND: "bash" #0 [ffff880037169db0] crash_kexec at ffffffff80268fd6 #1 [ffff880037169e80] __handle_sysrq at ffffffff803d50ed #2 [ffff880037169ec0] write_sysrq_trigger at ffffffff802f6fc5 #3 [ffff880037169ed0] proc_reg_write at ffffffff802f068b #4 [ffff880037169f10] vfs_write at ffffffff802b1aba #5 [ffff880037169f40] sys_write at ffffffff802b1c1f #6 [ffff880037169f80] system_call_fastpath at ffffffff8020bfbb RIP: 00007fa958991f60 RSP: 00007fff61330390 RFLAGS: 00010246 RAX: 0000000000000001 RBX: ffffffff8020bfbb RCX: 0000000000000001 RDX: 0000000000000002 RSI: 00007fa959284000 RDI: 0000000000000001 RBP: 0000000000000002 R8: 00007fa9592516f0 R9: 00007fa958c209c0 R10: 00007fa958c209c0 R11: 0000000000000246 R12: 00007fa958c1f780 R13: 00007fa959284000 R14: 0000000000000002 R15: 00000000595569d0 ORIG_RAX: 0000000000000001 CS: 0033 SS: 002bcrash>
Now it is clear what happened: The internal echo
command of Bash shell sent a character to
/proc/sysrq-trigger. After the corresponding
handler recognized this character, it invoked the
crash_kexec() function. This function called
panic() and Kdump saved a dump.
In addition to the basic GDB commands and the extended version of
bt, the crash utility defines many other commands
related to the structure of the Linux kernel. These commands understand
the internal data structures of the Linux kernel and present their
contents in a human readable format. For example, you can list the
tasks running at the moment of the crash with ps.
With sym, you can list all the kernel symbols with
the corresponding addresses, or inquire an individual symbol for its
value. With files, you can display all the open file
descriptors of a process. With kmem, you can display
details about the kernel memory usage. With vm, you
can inspect the virtual memory of a process, even at the level of
individual page mappings. The list of useful commands is very long and
many of these accept a wide range of options.
The commands that we mentioned reflect the functionality of the common
Linux commands, such as ps and
lsof. If you want to find out the exact sequence of
events with the debugger, you need to know how to use GDB and to have
strong debugging skills. Both of these are out of the scope of this
document. In addition, you need to understand the Linux kernel. Several
useful reference information sources are given at the end of this
document.
17.9 Advanced Kdump Configuration #
The configuration for Kdump is stored in
/etc/sysconfig/kdump. You can also use YaST to
configure it. Kdump configuration options are available under
› in . The following Kdump
options may be useful for you.
You can change the directory for the kernel dumps with the
KDUMP_SAVEDIR option. Keep in mind that the size of
kernel dumps can be very large. Kdump will refuse to save the dump
if the free disk space, subtracted by the estimated dump size, drops
below the value specified by the KDUMP_FREE_DISK_SIZE
option. Note that KDUMP_SAVEDIR understands the URL format
PROTOCOL://SPECIFICATION, where
PROTOCOL is one of file,
ftp, sftp, nfs or
cifs, and specification varies for each
protocol. For example, to save kernel dump on an FTP server, use the
following URL as a template:
ftp://username:password@ftp.example.com:123/var/crash.
Kernel dumps are usually huge and contain many pages that are not
necessary for analysis. With KDUMP_DUMPLEVEL option,
you can omit such pages. The option understands numeric value between 0
and 31. If you specify 0, the dump size will
be largest. If you specify 31, it will produce
the smallest dump. For a complete table of possible values, see the
manual page of kdump (man 7 kdump).
Sometimes it is very useful to make the size of the kernel dump smaller.
For example, if you want to transfer the dump over the network, or if you
need to save some disk space in the dump directory. This can be done with
KDUMP_DUMPFORMAT set to compressed. The
crash utility supports dynamic decompression of the
compressed dumps.
Important: Changes to the Kdump Configuration File
You always need to execute systemctl restart kdump
after you make manual changes to
/etc/sysconfig/kdump. Otherwise, these changes will
take effect next time you reboot the system.
17.10 For More Information #
There is no single comprehensive reference to Kexec and Kdump usage. However, there are helpful resources that deal with certain aspects:
For the Kexec utility usage, see the manual page of
kexec(man 8 kexec).IBM provides a comprehensive documentation on how to use dump tools on the z Systems architecture at http://www.ibm.com/developerworks/linux/linux390/development_documentation.html.
You can find general information about Kexec at http://www.ibm.com/developerworks/linux/library/l-kexec.html . Might be slightly outdated.
For more details on Kdump specific to openSUSE Leap, see http://ftp.suse.com/pub/people/tiwai/kdump-training/kdump-training.pdf .
An in-depth description of Kdump internals can be found at http://lse.sourceforge.net/kdump/documentation/ols2oo5-kdump-paper.pdf .
For more details on crash dump analysis and
debugging tools, use the following resources:
In addition to the info page of GDB (
info gdb), you might want to read the printable guides at http://sourceware.org/gdb/documentation/ .A white paper with a comprehensive description of the crash utility usage can be found at http://people.redhat.com/anderson/crash_whitepaper/.
The crash utility also features a comprehensive online help. Use
helpCOMMAND to display the online help forcommand.If you have the necessary Perl skills, you can use Alicia to make the debugging easier. This Perl-based front-end to the crash utility can be found at http://alicia.sourceforge.net/ .
If you prefer to use Python instead, you should install Pykdump. This package helps you control GDB through Python scripts and can be downloaded from http://sf.net/projects/pykdump .
A very comprehensive overview of the Linux kernel internals is given in Understanding the Linux Kernel by Daniel P. Bovet and Marco Cesati (ISBN 978-0-596-00565-8).